Desbravando o Pandas - Parte 7 - Agrupamento e ordenação
Como agrupar e/ou ordenar DataFrames baseando-se em atributos.

Neste documento continuaremos explorarando os conceitos iniciais da biblioteca Pandas. Para acompanhamento utilizaremos a mesma base do 🔗Desbravando o Pandas - Parte 1 - Estrutura de dados e seguirei com as mesmas estruturas criadas previamente.
Agrupamento e ordenação
No pandas, os métodos groupby() e sort_values() são operações fundamentais para organizar e extrair informações. Assim como no SQL as operações de GROUP BY e ORDER BY estão entre as mais utilizadas.
Agrupamento
.groupby()
O agrupamento no Pandas é realizado com o método groupby(), que permite segmentar um conjunto de dados com base em uma ou mais colunas. Essa técnica é útil para resumir informações, como calcular médias, somas, contagens e outras estatísticas por categoria. Por exemplo, em um conjunto de dados de vendas, podemos agrupar por categoria de produto e calcular o total vendido para cada uma.
O agrupamento acontece pelo método groupby() e ele é semelhante ao GROUP BY do SQL.
Funções podem então ser aplicadas para os elementos de cada grupo, de modo que os resultados de cada grupo são combinados.
1
2
3
df_grupo = df_data.groupby('Região')
df_grupo
 Objeto de agrupamento criado
Objeto de agrupamento criado df_grupo
O groupby não retorna um novo DataFrame, mas sim um objeto de agrupamento, que pode ser processado posteriormente com funções como sum(), mean(), count(), entre outras. Esse método é muito útil para agregar dados e identificar padrões em grandes conjuntos de informações.
1
df_grupo.groups
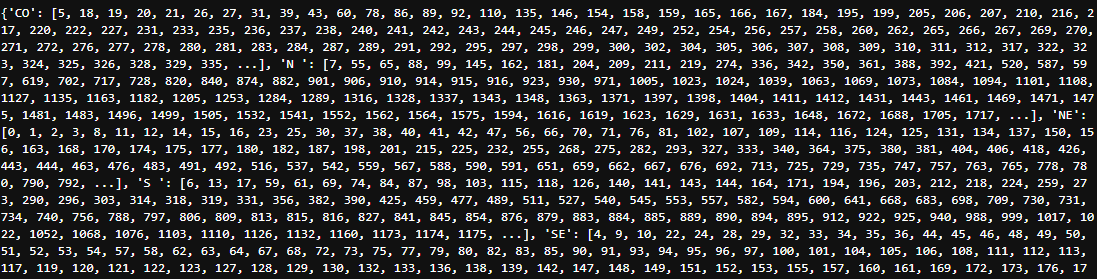 Retorno do dicionário gerado utilizando o atributo
Retorno do dicionário gerado utilizando o atributo groups no agrupamento df_grupo
O atributo groups retorna um dicionário do objeto groupby(). Este contém o Index para cada valor do agrupamento. Da seguinte forma:
- As chaves são os valores únicos das colunas usadas para agrupar (Neste exemplo a coluna Região).
- Os valores são listas com os índices das linhas correspondentes a cada grupo.
1
df_grupo.indices
 Retorno do dicionário gerado utilizando o atributo
Retorno do dicionário gerado utilizando o atributo indices no agrupamento df_grupo
O atributo indices de um objeto groupby() retorna um dicionário, assim como groups, mas com uma diferença:
- As chaves são os valores únicos das colunas usadas para agrupar (Neste exemplo a coluna Região).
- Os valores são arrays NumPy contendo os índices das linhas correspondentes a cada grupo.
Se quisermos no nosso tratamento retornar apenas um valor do grupo utilizado, podemos fazer o seguinte:
Supondo que nosso objetivo seja o agrupamento Região mas apenas o valor Centro Oeste (CO).
1
2
## Retornando um DataFrame contendo o grupo do agrupamento utilizando 'CO'
df_grupo.get_group('CO')
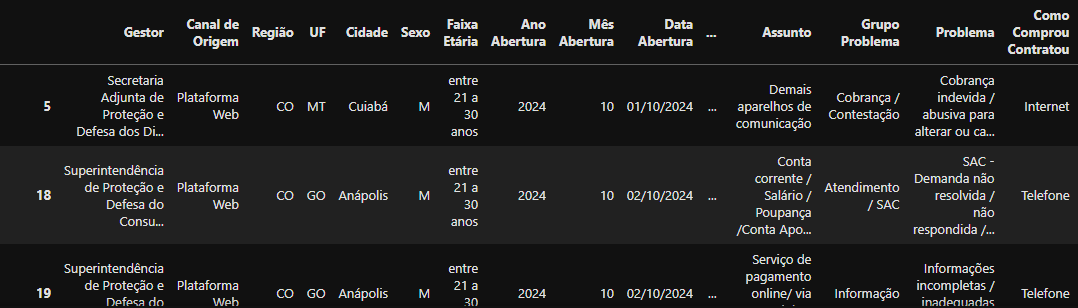 Retorno do DataFrame utilizando o método
Retorno do DataFrame utilizando o método get_group() pegando a ‘Região’ de ‘CO’ (Centro Oeste)
Também é possível utilizar a operação de análise descritiva (Mostrados na parte 5) utilizando também describe() e todos atributos individuais.
1
df_grupo.describe()
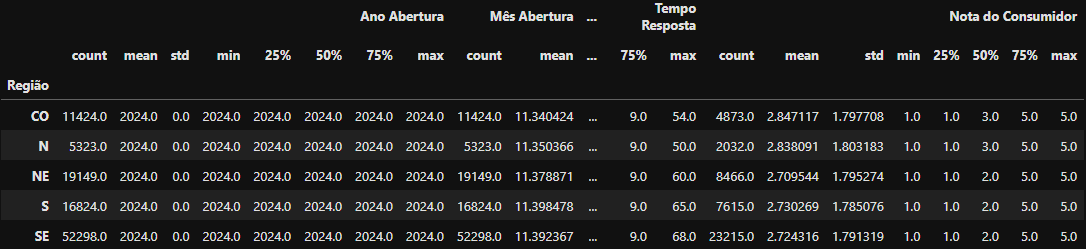 Retorno do DataFrame utilizando o método
Retorno do DataFrame utilizando o método describe() no agrupamento df_grupo
Podemos também agrupar por mais de uma coluna, utilizando o próprio groupby() podemos por exemplo:
Qual a média das avaliações das reclamações pra cada Região e Como Comprou Contratou?
1
2
3
4
5
## Agrupa primeiro por 'Região'
## Agrupa segundo por 'Como comprou Contratou'
df_media_regiao = df_data.groupby(['Região','Como Comprou Contratou'])
## Utilizando a função agregadora de média
df_media_regiao['Nota do Consumidor'].mean()
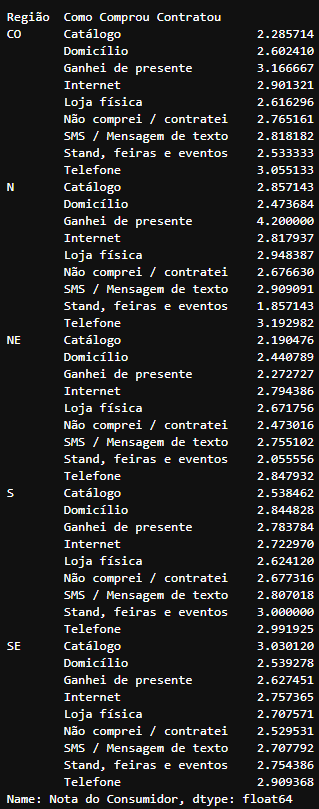 Retorno do agrupamento
Retorno do agrupamento df_media_regiao utilizando duas colunas ‘Região’ e ‘Como Comprou Contratou’ e a média das nótas dos consumidores
.agg()
O método agg() permite aplicar múltiplas funções de agregação em colunas específicas de um DataFrame ou Series. Ele é muito útil quando queremos aplicar diferentes funções agregadoras a diferentes colunas ao mesmo tempo.
Por exemplo, tendo o seguinte DataFrame:
1
2
3
4
5
6
7
df = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[None, None, None]],
columns=['A','B','C'])
df
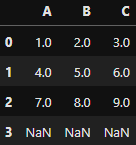 Retorno do DataFrame criado
Retorno do DataFrame criado df
Podemos aplicar diferentes operações, da seguinte forma:
1
df.agg([sum, min]) ## Ignora o NaN
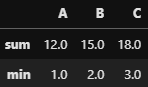 Retorno das funções de agregações
Retorno das funções de agregações sum e min
Podemos também utilizar juntamente com a operação groupby()
1
df_grupo['Nota do Consumidor'].agg([min,max])
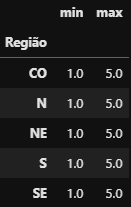 Retorno das funções de agregações
Retorno das funções de agregações min e max com o agrupamento df_grupo e o método agg()
Ordenação
A ordenação no Pandas é feita com o método sort_values(), que organiza as linhas de um DataFrame com base nos valores de uma ou mais colunas. Podemos ordenar de forma crescente ou decrescente, dependendo da necessidade da análise.
A função básica é : df.sort_values(by="coluna", ascending=True|False)
- ascending=True → Define a ordem crescente.
- ascending=False → Define a ordem decrescente.
1
2
3
4
5
6
7
df_rh = pd.DataFrame({
"Nome": ["Lucas", "Ana", "Pedro", "Mariana"],
"Idade": [30, 25, 40, 35],
"Salario": [4000, 7000, 4000, 8000]
})
df_rh
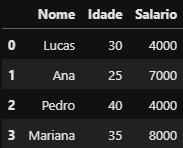 DataFrame criado
DataFrame criado df_rh
Como ordenar o DataFrame df_rh pelo salário?
- Do Menor Salário → Maior Salário:
1
2
## Crescente
df_rh.sort_values(by='Salario', ascending=True)
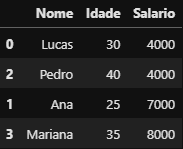 DataFrame
DataFrame df_rh ordenado em ordem crescente Menor Salário → Maior Salário
- Do Maior Salário → Menor Salário:
1
2
## Decrescente
df_rh.sort_values(by='Salario', ascending=False)
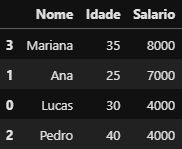 DataFrame
DataFrame df_rh ordenado em ordem decrescente Maior Salário → Menor Salário
Podemos aplicar o método sort_values() por mais de uma coluna.
Se quisermos ordenar de forma Crescente o valor do Salário e de forma Descrescente a idade. Podemos seguir o seguinte exemplo
1
2
3
## Ordenando o Salário de forma crescente (Menor → Maior)
## Ordenando a Idade de forma decrescente (Maior → Menor)
df_rh.sort_values(by=['Salario','Idade'], ascending=[True,False])
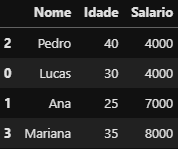 DataFrame
DataFrame df_rh ordenado em ordem crescente Menor Salário → Maior Salário pelo Salário e em ordem decrescente Maior Idade → Menor Idade
Note que o DataFrame original não foi alterado:
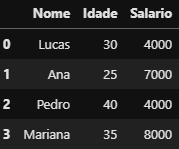 DataFrame
DataFrame df_rh não foi alterado
Para alterar o DataFrame original
df_rhé necessário o comandoinplace=True.
Uma abordagem comum é agrupar os dados e, em seguida, ordená-los com base nos valores agregados. Por exemplo, ao analisar um conjunto de dados de vendas, podemos primeiro agrupar por região e calcular o faturamento total, depois ordenar do maior para o menor, destacando as regiões com melhor desempenho.
Esses dois métodos são fundamentais para transformar grandes volumes de dados, permitindo análises mais detalhadas e decisões mais informadas
Para download do notebook utilizado, acesse o 🔗Link