Desbravando o Pandas - Parte 5 - Limpeza e estatísticas descritivas
Neste post, exploraremos as técnicas básicas de limpeza de dados, como tratamento de valores ausentes, correção de dados inconsistentes e a transformação de tipos de dados.

Neste documento continuaremos explorarando os conceitos iniciais da biblioteca Pandas. Para acompanhamento utilizaremos a mesma base do 🔗Desbravando o Pandas - Parte 1 - Estrutura de dados e seguirei com as mesmas estruturas criadas previamente.
Limpeza
A limpeza de dados é uma etapa essencial no processo de análise de dados, garantindo que as informações utilizadas sejam precisas, consistentes e utilizáveis. Dados brutos frequentemente contêm erros, valores ausentes, duplicados ou inconsistências que podem distorcer os resultados de qualquer análise. Portanto, a limpeza não apenas melhora a qualidade dos dados, mas também otimiza a eficiência dos modelos preditivos e das decisões baseadas em dados. Neste post, exploraremos as técnicas básicas de limpeza de dados, como tratamento de valores ausentes, correção de dados inconsistentes e a transformação de tipos de dados.
Olhando mais de perto nosso DataFrame df_data temos que, ele contém 105.018 linhas e 30 colunas
1
df_data.shape
 Número de linhas e colunas do DataFrame
Número de linhas e colunas do DataFrame df_data
Dos quais:
- Existem colunas contendo valores nulos (ex: ‘Nota do Consumidor’);
- Existem colunas contendo campos com tipo errado (ex: ‘Data Abertura’);
- Existem colunas contendo caracteres especiais (ex: ‘Faixa Etária’), dificultando o uso de certas funções;
1
df_data.info()
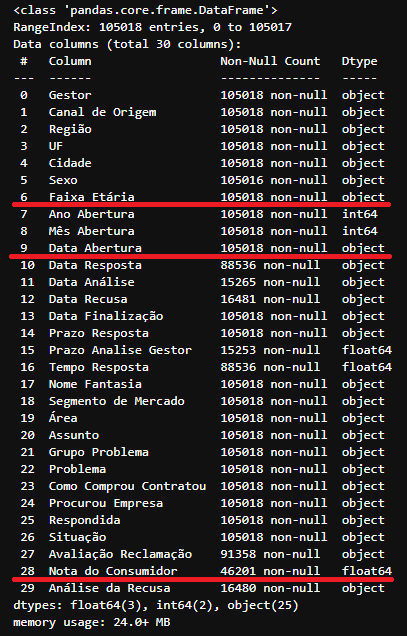 Informações do DataFrame
Informações do DataFrame df_data
Por questão de COMPARAÇÃO utilizaremos uma cópia do DataFrame df_data:
1
df_tratado = df_data.copy()
Tratando colunas com dados faltantes (NaN)
No nosso DataFrame df_tratado existem alguns valores nulos (NaN) em diversas colunas. Supondo que a área de negócios impôs a necessidade de tratar estes valores por conta de alguma regra de negócio.
Como isso seria feito?
1. Remover LINHAS contendo QUALQUER coluna NaN
Caso exista essa necessidade, de deixar apenas registros com 100% de preenchimento em todas as colunas. Usa-se o método dropna(), este remove todas as linhas que possuem valores nulos de um DataFrame.
1
df_tratado.dropna().info() ## Remove todas as linhas que possuem valores nulos
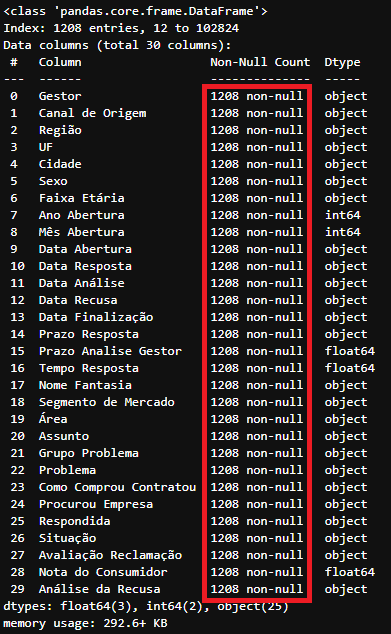 Resultado após a remoção das linhas que contenham ao menos um nulo em alguma coluna do DataFrame
Resultado após a remoção das linhas que contenham ao menos um nulo em alguma coluna do DataFrame df_tratado
Note que após o uso do método dropna() apenas 1.208 linhas foram retornadas e não existe mais nenhuma coluna com valores ‘Non-Null Count’ diferente de 1.208 (Total de linhas).
2. Remover COLUNAS com valores NaN
Caso exista essa necessidade, de deixar apenas colunas com 100% de preenchimento em todas as 105.018 linhas. Usa-se o método dropna() juntamente com o parâmetro axis=1, da seguinte forma DataFrame.dropna(axis=1) este remove todas as colunas que contenham ao menos 1 valor NaN deixando apenas os campos onde o total de valores ‘Non-Null Count’ é igual ao total de linhas no DataFrame.
O Parâmetro
axis=0|1indica que a ação em questão será realizado na LINHA (axis=0) ou na COLUNA (axis=1).
1
df_tratado.dropna(axis=1).info()
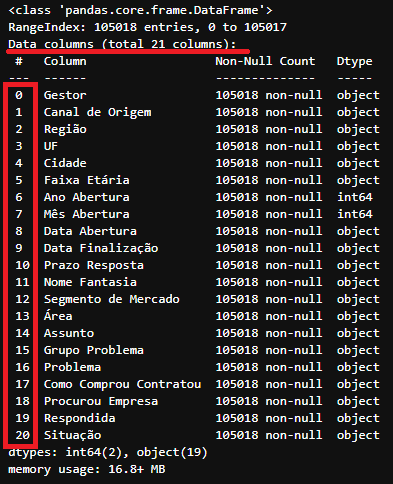 Resultado após a remoção das colunas que contenham ao menos um nulo em alguma das linhas do DataFrame
Resultado após a remoção das colunas que contenham ao menos um nulo em alguma das linhas do DataFrame df_tratado
note que após o uso do método dropna(axis=1) apenas 21 colunas restaram. Ou seja, 9 colunas do DataFrame df_tratado continha valores do tipo NaN em ao menos 1 linha.
3. Preencher valores NaN
É possível também substituir valores NaN por outro valor desejado.
Por exemplo, existe a necessidade de substituir todos os valores NaN pela string ‘Sem Valor’. Podemos cumprir este requisito passando a string desejada dentro do método fillna() da seguinte forma:
1
df_tratado.fillna('Sem Valor').info()
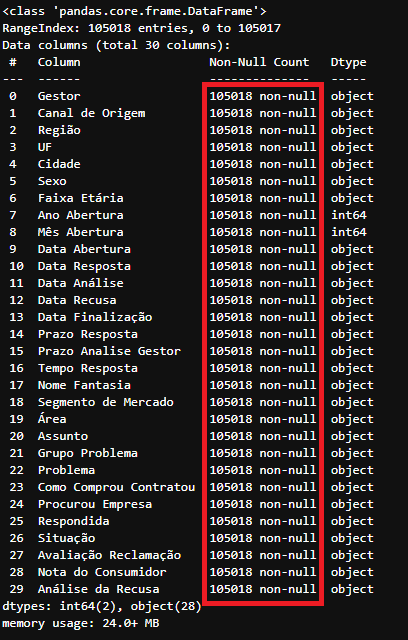 Resultado após a troca dos valores nulos pela string ‘Sem Valor’ do DataFrame
Resultado após a troca dos valores nulos pela string ‘Sem Valor’ do DataFrame df_tratado
Note que não existe mais colunas com o valor ‘Non-Null Count’ diferente de 105.018.
Olhando mais de perto:
1
df_tratado.fillna('Sem Valor').iloc[1] ##Retornando a linha 1 do DataFrame 'df_tratado'
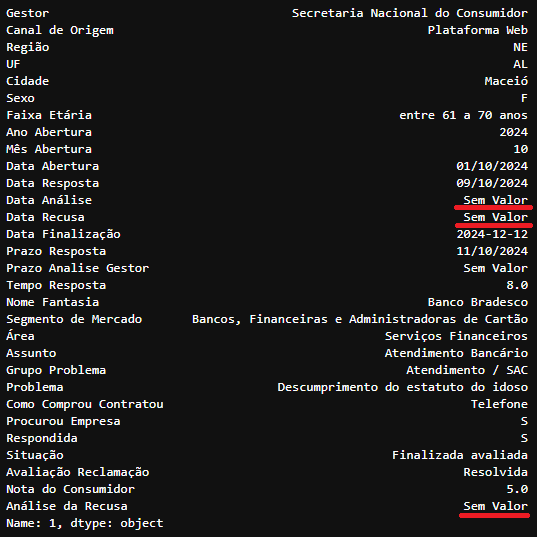 Detalhado do Index 1 após a troca dos valores nulos pela string ‘Sem Valor’ do DataFrame
Detalhado do Index 1 após a troca dos valores nulos pela string ‘Sem Valor’ do DataFrame df_tratado
As colunas ‘Data Análise’, ‘Data Recusa’, ‘Prazo Analise Gestor’ e ‘Análise da Recusa’ que continham NaN foram substituidas pela string ‘Sem Valor’
No nosso caso, vamos salvar a substituição feita de NaN para outra string mas apenas na coluna ‘Análise da Recusa’:
1
2
df_tratado['Análise da Recusa'] = df_tratado['Análise da Recusa'].fillna('Sem Valor')
df_tratado['Análise da Recusa'].unique()
 Resultado após a troca dos valores nulos pela string ‘Sem Valor’ da coluna ‘Análise da Recusa’ do DataFrame
Resultado após a troca dos valores nulos pela string ‘Sem Valor’ da coluna ‘Análise da Recusa’ do DataFrame df_tratado
Conversão de tipos de colunas
Muitas vezes os dados recebidos estarão fora de padrões pré-definidos, podendo conter erros de digitação e tipos de dados diferentes do usual e existirá a necessidade de tratá-los e padronizá-los para um tipo mais adequada.
1
df_tratado[['Data Abertura','Data Resposta','Data Análise','Data Recusa']].info()
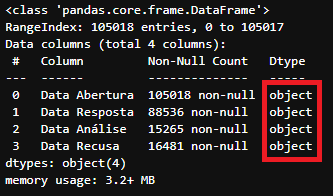 Tipos das colunas ‘Data Abertura’,’Data Resposta’,’Data Análise’,’Data Recusa’ do DataFrame
Tipos das colunas ‘Data Abertura’,’Data Resposta’,’Data Análise’,’Data Recusa’ do DataFrame df_tratado
Note que no nosso DataFrame df_tratado todas as colunas de datas estão no tipo object. Existe um tipo de atributo no Pandas para data, este é o tipo datetime e podemos converter os tipos da seguinte forma:
1
pd.to_datetime(df_tratado['Data Abertura'])
 Erro na função
Erro na função to_datetime devido ao padrão de data repassado
Este erro ocorre pois o formato de data do arquivo .csv esta diferente DD/MM/YYYY do padrão utilizado YYYY-MM-DD. Esta correção pode ser feito passando o parâmetro format=%d/%m/%Y:
1
pd.to_datetime(df_tratado['Data Abertura'],format='%d/%m/%Y')
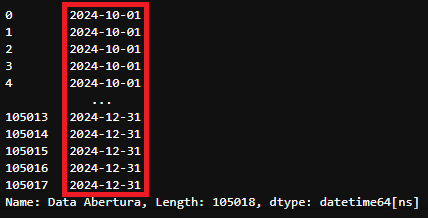 Retorno da coluna ‘Data Abertura’ após a alteração do tipo
Retorno da coluna ‘Data Abertura’ após a alteração do tipo
Vamos alterar todas as colunas de datas para o formato datetime:
1
2
3
4
5
6
7
## Alterando o formato dos campo 'Data Abertura','Data Resposta','Data Análise' e 'Data Recusa' para datetime
df_tratado['Data Abertura'] = pd.to_datetime(df_tratado['Data Abertura'],format='%d/%m/%Y')
df_tratado['Data Resposta'] = pd.to_datetime(df_tratado['Data Resposta'],format='%d/%m/%Y')
df_tratado['Data Análise'] = pd.to_datetime(df_tratado['Data Abertura'],format='%d/%m/%Y')
df_tratado['Data Recusa'] = pd.to_datetime(df_tratado['Data Recusa'],format='%d/%m/%Y')
df_tratado.info()
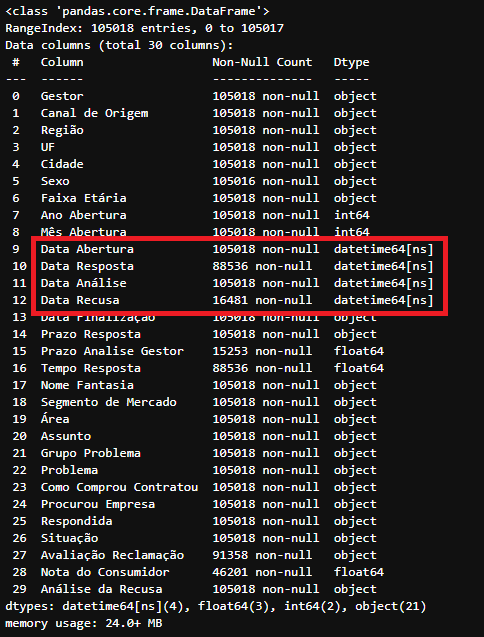 Informação das colunas após a alteração do tipo dos campos de data para datetime no DataFrame
Informação das colunas após a alteração do tipo dos campos de data para datetime no DataFrame df_tratado
Repare também que a nossa coluna ‘Nota do Consumidor’ é do tipo float64.
1
df_tratado['Nota do Consumidor'].unique()
 Campos únicos da coluna ‘Nota do Consumidor’
Campos únicos da coluna ‘Nota do Consumidor’
Faz mais sentido alterarmos para o tipo int32 já que a coluna em si varia apenas entre os valores 1,2,3,4 e 5. Para isto primeiro vamos tratar o valor NaN da coluna e em seguida converter para o tipo correto.
1
2
df_tratado['Nota do Consumidor'] = df_tratado['Nota do Consumidor'].fillna(0)
df_tratado['Nota do Consumidor'].unique()
 Campos únicos da coluna ‘Nota do Consumidor’ após alteração dos nulos para 0
Campos únicos da coluna ‘Nota do Consumidor’ após alteração dos nulos para 0
Agora a alteração do tipo deste atributo pode ser feita utilizando a função de conversão astype(type) :
1
2
df_tratado['Nota do Consumidor'] = df_tratado['Nota do Consumidor'].astype(int)
df_tratado.info()
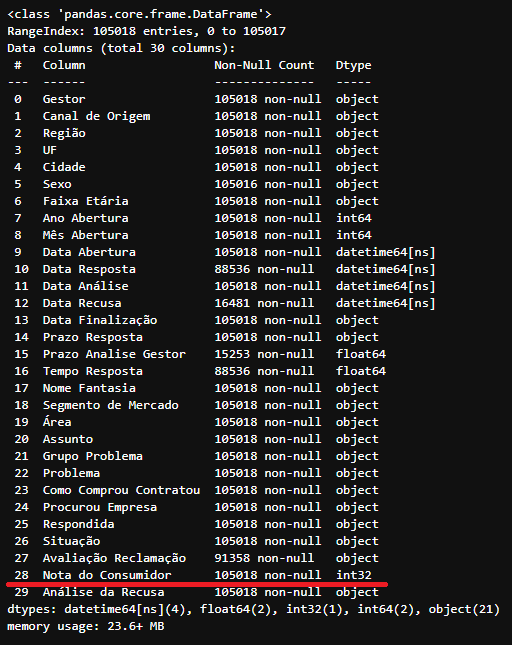 Informação das colunas após a alteração do tipo do campo ‘Nota do Consumidor’ de float64 para int32 no DataFrame
Informação das colunas após a alteração do tipo do campo ‘Nota do Consumidor’ de float64 para int32 no DataFrame df_tratado
Como alterar varias colunas de uma vez?
Para este objetivo, utilizaremos um DataFrame fictício apenas para exemplificar.
1
2
df_exemplo = pd.read_excel('./Base de dados/Valores Contratos.xlsx', sheet_name='Plan1')
df_exemplo.info()
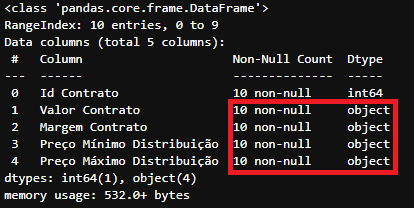 Informação das colunas no DataFrame
Informação das colunas no DataFrame df_exemplo
Os tipos de ‘Valor Contrato’, ‘Margem Contrato’, ‘Preço Mínimo Distribuição’ e ‘Preço Máximo Distribuição’ não estão representando números e sim strings.
Para fazermos essa correção de forma mais eficaz, podemos utilizar a estrutura de repetição for (Laços de repetição serão exemplificados no futuro) juntamente com a função to_numeric():
1
2
3
4
for coluna in ['Valor Contrato', 'Margem Contrato', 'Preço Mínimo Distribuição','Preço Máximo Distribuição']:
df_exemplo[coluna] = pd.to_numeric(df_exemplo[coluna], errors='coerce')
df_exemplo.info()
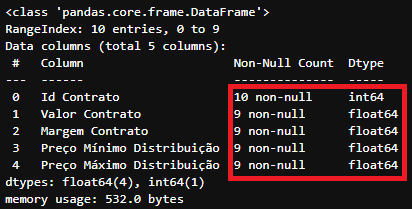 Informação das colunas no DataFrame
Informação das colunas no DataFrame df_exemplo após alteração de todos valores que deveriam ser numericos de object para float64
A função to_numeric() possui o parâmetro errors='ignore'|'raise'|'coerce'. Este parâmetro indica como a conversão deve prosseguir caso encontre algum registro no qual a conversão se torna impossível para a função.
- raise: A análise inválida gerará uma exceção;
- coerce: A análise inválida será retornará
NaNpara o registro; - ignore: A análise inválida retornará o registro original;
No nosso caso utilizamos o parâmetro errors='coerce' o que fez a conversão retornar o valor NaN para registros não tratados pela função:
1
df_exemplo
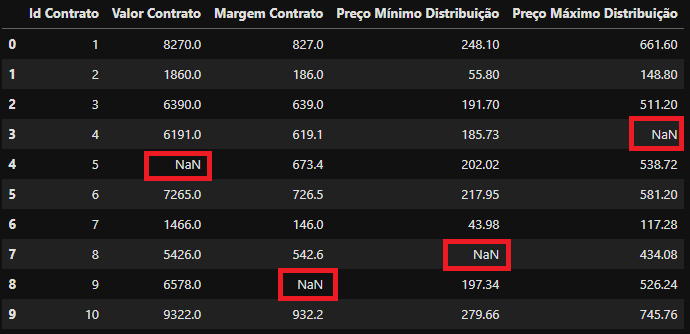 DataFrame
DataFrame df_exemplo após a alteração feita
Estatísticas descritivas
O método describe() exibe várias estatísticas descritivas sobre um determinado DataFrame ou para uma Series.
1
df_exemplo.describe()
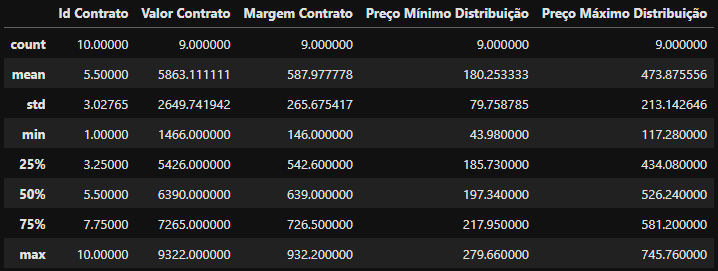 Estatísticas descritivas do DataFrame
Estatísticas descritivas do DataFrame df_exemplo
Como o resultado do método describe() é outro DataFrame, podemos então fazer filtro nele:
Por exemplo, se quisermos apenas a coluna ‘Margem Contrato’, podemos fazer filtragem direta
1
df_exemplo['Margem Contrato'].describe()
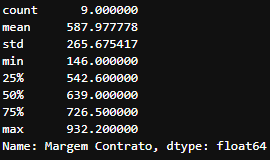 Estatísticas descritivas da coluna ‘Margem Contrato’
Estatísticas descritivas da coluna ‘Margem Contrato’
Desta forma obteremos as mesmas descrições mas apenas da coluna interessada.
Também podemos selecionar apenas as estatísticas desejadas utilizando o .loc
1
df_exemplo.describe().loc[['min','mean','max']]
 Estatísticas descritivas
Estatísticas descritivas min,mean e max do dataframe df_exemplo
Semelhante, também podemos selecionar apenas as estatísticas desejadas das colunas desejadas com .loc
1
df_exemplo.describe().loc[['min','mean','max'],['Margem Contrato','Valor Contrato']]
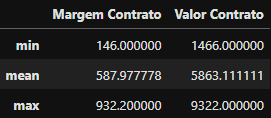 Estatísticas descritivas
Estatísticas descritivas min,mean e max das colunas ‘Margem Contrato’ e ‘Valor Contrato’
As estatísticas std,mean,min,max e todas as outras do método describe() podem ser computadas individualmentes.
Se quisermos saber qual o preço mínimo de distribuição?
1
df_exemplo['Preço Mínimo Distribuição'].min()
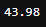 Estatísticas descritivas
Estatísticas descritivas min da coluna ‘Preço Mínimo Distribuição’
Se quis quisermos saber qual o desvio padrão do valor do contrato?
1
df_exemplo['Valor Contrato'].std()
 Estatísticas descritivas
Estatísticas descritivas std da coluna ‘Valor Contrato’
Qualquer estatística do método
describe()pode ser gerado individualmente como estes.
Outro método útil para aferir estatísticas básicas do seu DataFrame é a contagem de frequência.
Para isso o método value_counts() conta a frequência dos valores de uma dada variável da seguinte maneira:
1
2
## Retorna em ordem decrescente uma Series com a quantidade de linhas (No nosso caso reclamações do Consumidor Gov) para cada UF
df_data['UF'].value_counts()
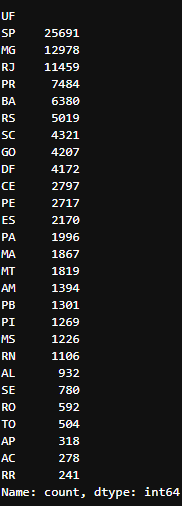 Contagem da frequência de linhas da coluna ‘UF’ do DataFrame
Contagem da frequência de linhas da coluna ‘UF’ do DataFrame df_data
Caso seja necessário um DataFrame, podemos utilizar o método to_frame() para esse objetivo:
1
2
## Convertendo a Series para DataFrame com o método to_frame()
df_data['UF'].value_counts().to_frame()
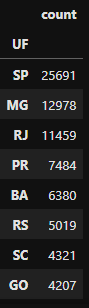 Transformando a Series contendo a contagem da frequência de linhas da coluna ‘UF’ do DataFrame
Transformando a Series contendo a contagem da frequência de linhas da coluna ‘UF’ do DataFrame df_data em um DataFrame
No nosso caso a UF com mais reclamações é São Paulo e a com menos reclamações é Roraima.
Para download do notebook utilizado, acesse o 🔗Link