Desbravando o Pandas - Parte 4 - Filtragem
Neste post mostrarei o que talvez seja uma das partes mais utilizadas no tratamento de dados, a FILTRAGEM.

Neste documento continuaremos explorarando os conceitos iniciais da biblioteca Pandas. Para acompanhamento utilizaremos a mesma base do 🔗Desbravando o Pandas - Parte 1 - Estrutura de dados e seguirei com as mesmas estruturas criadas previamente.
Filtragem
Durante a análise exploratória dos dados, frequentemente será necessário filtrar amostras, a partir de certas condições, para fins de análise mais específica. Existe algumas maneiras de fazermos isso como as mostradas a seguir:
Filtragem condicional direta
Supondo que nosso objetivo seja trazer apenas as reclamações do site “ConsumidorGov” do estádo GOIÁS, como seria feito?
Para fazer essa selação condicional, é necessário buscar o descritivo que representa SÃO PAULO e como esta escrita dentro da massa de dados, neste caso utilizaremos a seleção da coluna UF juntamente com o método unique(), este é responsável por trazer uma array com os campos distintos para cada valor do campo selecionado.
1
2
3
## Mostra todos os estados com reclamações no site "Consumidor Gov".
## Mostra os únicos (unique) valores para a coluna 'UF'.
df_data['UF'].unique()
 Valores únicos da coluna ‘UF’ do DataFrame
Valores únicos da coluna ‘UF’ do DataFrame df_data
Podemos observar que o nosso objetivo então é fazer a filtragem condicional/direta utilizando o valor ‘SP’ da coluna UF. Podemos fazer isto da seguinte forma:
1
2
## Comparação da coluna 'UF' com o valor 'SP'
df_data['UF'] == 'SP'
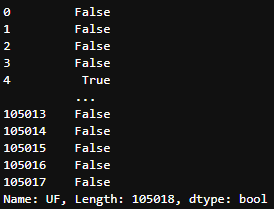 Series retornada da filtragem da coluna ‘UF’
Series retornada da filtragem da coluna ‘UF’
Repare que o retorno é feito **linha a linha** através de uma Series(‘array’) de booleans mostrando se a linha em questão respeita(TRUE) ou não respeita(FALSE) a condição proposta UF = 'SP'.
Como filtrar então o DataFrame df_data para obter apenas as linhas que contém o campo UF igual a ‘SP’?
1
2
3
## Armazenando a series retornada em uma variável
selecao = df_data['UF'] == 'SP'
selecao
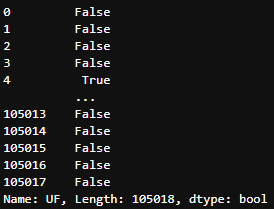 Series retornada da filtragem da coluna ‘UF’ armazenada na variável
Series retornada da filtragem da coluna ‘UF’ armazenada na variável selecao
1
2
## Aplicando a filtragem em todos os registros do DataFrame 'df_data' utilizando a series de booleano 'selecao'
df_data[selecao]
 Valor ÚNICO retornado após a Series
Valor ÚNICO retornado após a Series selecao ser aplicada na filtragem do DataFrane df_data
Desta forma, o retorno do DataFrame é apenas com as linhas onde o campo UF é igual a ‘SP’
Também é possível utilizando o comando
.loc[selecao]para obter o mesmo resultado.
Filtragem com o método query()
Também é possível utilizar o método query, este filtra linhas de um DataFrame baseando-se em uma pergunta(Query).
1
df_data.query('UF == "SP"')
 Valor ÚNICO retornado após a Series
Valor ÚNICO retornado após a Series selecao ser aplicada na filtragem do DataFrane df_data utilizando o método query()
Uma boa prática é sempre salvar o DataFrame em uma nova variável. Isso simplifica a complexidade do código para futuras análises feitas.
1
2
consumidor_sp = df_data.query('UF == "SP"')
consumidor_sp
Valor ÚNICO retornado após a Series selecao ser aplicada na filtragem do DataFrane df_data utilizando o método query()
Note, que os índices das linhas mesmo após a filtragem continuam sendo os mesmos do DataFrame df_data. Em algumas situações, manter esta informação é importante.
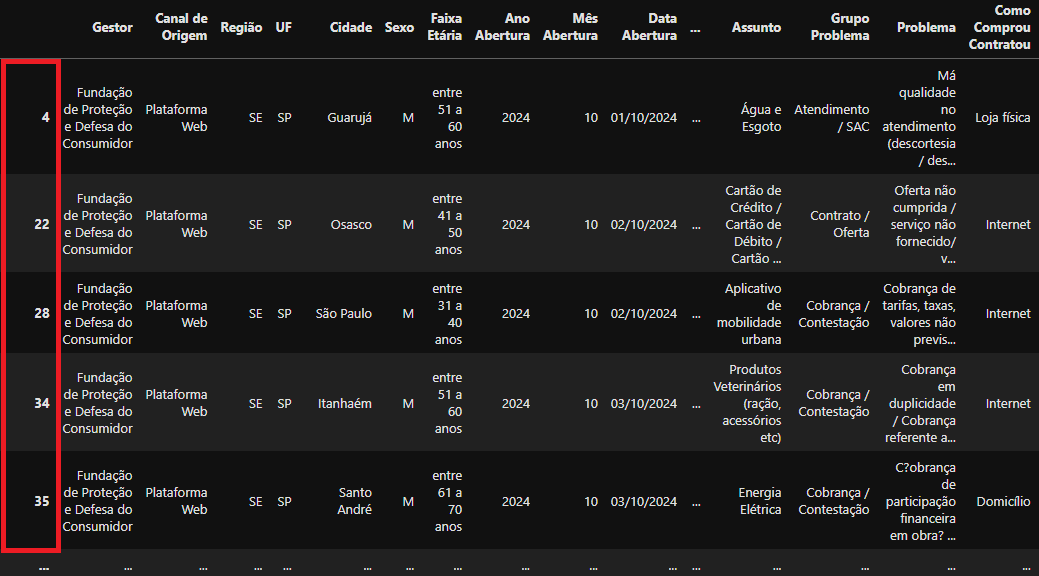 Novo DataFrame
Novo DataFrame consumidor_sp contém o index das linhas do DataFrame original df_data mantidos
Caso seja necessário resetar os índices do Data Frame novo filtrado, use o método reset_index.
1
consumidor_sp.reset_index()
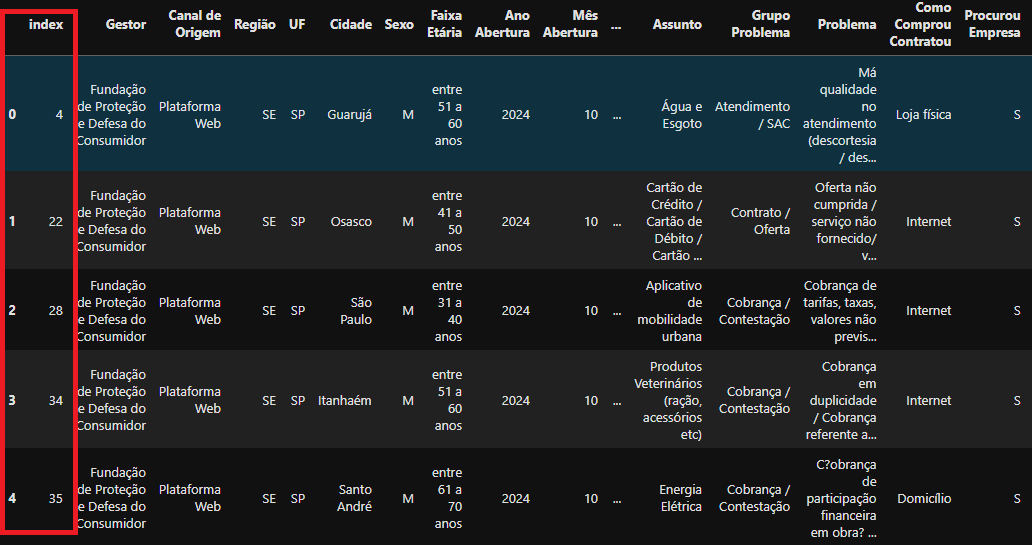 Novo DataFrame
Novo DataFrame consumidor_sp com o Index resetado variando entre 0 até n° linhas - 1
Note que o retorno mantém o antigo INDEX como coluna, caso você queira remover este do novo DataFrame utilize o parâmetro drop=True no método reset_index()
1
consumidor_sp.reset_index(drop = True).head()
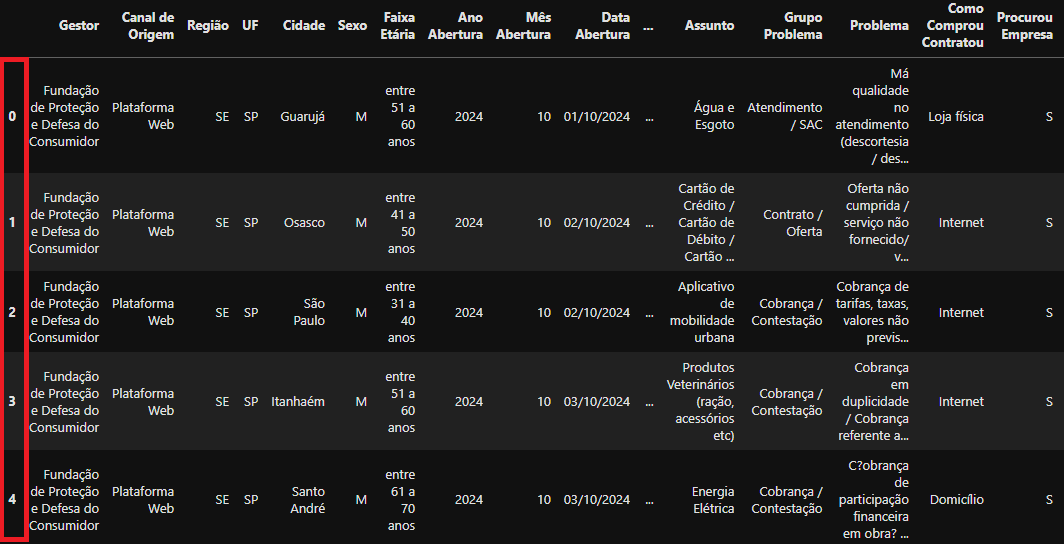 Novo DataFrame
Novo DataFrame consumidor_sp com o Index resetado variando entre 0 até n° linhas - 1 e a coluna preservada de Index removida
O DataFrame
consumidor_spnão foi alterado, caso seja necessário alterar é preciso utilizar o parâmetroinplace=True.
Filtragem com multiplas condicionais
Em Pandas, você pode filtrar um DataFrame com múltiplas condições usando operadores lógicos como:
&(AND) → Ambas as condições devem ser verdadeiras;|(OR) → Ao menos uma condição deve ser verdadeira;~(NOT) → Inverte a condição;
É importante que cada condição esteja em parênteses
Por exemplo, se quisermos todas as reclamações do .csv do Consumidor GOV do estado de GOIÁS (GO) que contenha nota menor ou igual a 3, podemos obter esse retorno da seguinte forma:
1
df_data[(df_data['UF'] == 'GO') & (df_data['Nota do Consumidor'] <= 3.0)] ##Consumidor GOV do estado de GOIÁS (GO) que contenha nota menor ou igual a 3
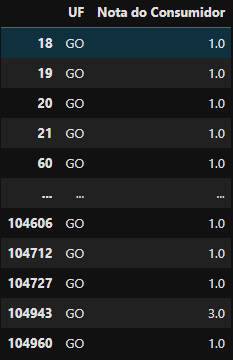 Retorno da filtragem com multiplas condicionais, apenas a reclamações do estado de Goiás e com nota menor ou igual a 3. Um total de 846 linhas foram retornadas
Retorno da filtragem com multiplas condicionais, apenas a reclamações do estado de Goiás e com nota menor ou igual a 3. Um total de 846 linhas foram retornadas
Também é possível utilizar o método
query()para fazer filtragem com multiplas condicionais. Porém, não é possível neste caso em específico devido a coluna Nota do Consumidor possuir caracteres invádios para o método (Cedilha, acentos ou espaços).
Detalhando a filtragem com múltiplas condicionais
A PRIMEIRA comparação (df_data['UF'] == 'GO') checa linha a linha do DataFrame, quais são aqueles cujo o estado é GOIÁS e nenhuma verificação de Nota do Consumidor é feita neste momento. Como resultado, temos uma Series de booleans com apenas esta filtragem.
A SEGUNDA comparação (df_data['Nota do Consumidor'] <= 3.0) checa linha a linha do DataFrame, quais são aquelas reclamações cujo a Nota do Consumidor é menor ou igual a 3.0 e nenhuma verificação de UF é feita neste momento. Como resultado, temos uma Series de booleans com apenas esta filtragem.
Por fim a PRIMEIRA e SEGUNDA comparação são unidas pelo operador lógico & (AND) retornando assim uma terceira Series de booleans fazendo a comparação completa.
Tal abordagem pode ser INEFICIENTE, uma vez que, para cada condição, estamos varrendo todas as linhas do DataFrame df_data (Ou seja, a varredura neste exemplo em específico é feita 3X). O Pandas tentará otimizar o máximo possível por trás dos pano porém, se tivermos uma base muito grande, tal abordagem se tornará mais INEFICIENTE ainda.
Logo, poderíamos fazer a filtragem utilizando múltiplos condicionais por partes:
- Podemos fazer primeiro o filtro
(df_data['UF'] == 'GO')trazendo assim primeiro, todos as linhas com o estado igual a GOIÁS:
1
2
filtro_consumidores_goias = df_data[(df_data['UF'] == 'GO')]
filtro_consumidores_goias
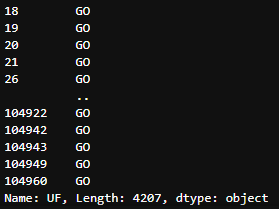 Retorno da filtragem com
Retorno da filtragem com dt_data['UF'] == 'GO'
Logo, o DataFrame filtro_consumidores_goias contém 4.207 linhas.
- Em seguida, aplicaremos o segundo filtro em cima do DataFrame
filtro_consumidores_goias. Portanto, a busca dos registros com Nota do Consumidor menor ou igual a 3.0 ((df_data['Nota do Consumidor'] <= 3.0)) será feita apenas em cima dos 4.207 registros (Ao invés das 105.018 linhas anteriores).
1
2
filtro_consumidores_goias_nota_baixa = filtro_consumidores_goias[(df_data['Nota do Consumidor'] <= 3.0)]
filtro_consumidores_goias_nota_baixa
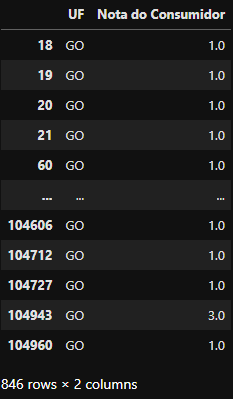 Retorno da filtragem com
Retorno da filtragem com df_data['Nota do Consumidor'] <= 3.0 feita em cima do DataFrame filtro_consumidores_goias com a filtragem aplicada dt_data['UF'] == 'GO'
Obtemos assim então, o mesmo resultado conseguido previamente (846 linas). Este método economizou busca desnecessária sendo mais eficiente em casos onde a consulta envolve bases gigantes com milhões de linhas.
Filtragem com listas
Se quisermos filtrar apenas as reclamações de compras feitas nas UF’s ‘GO’, ‘SP’, ‘RO’ e ‘MT’, ao invés de fazer a filtragem caso a caso podemos criar uma variável do tipo lista em python e repassar para filtragem:
1
2
lista_uf = ['GO','SP','RO','MT'] ## Criando lista contendo as UF's 'GO', 'SP', 'RO' e MT
lista_uf
 Lista
Lista lista_uf contendo as UF’s ‘GO’, ‘SP’, ‘RO’ e ‘MT’
Agora também podemos repassar esta lista na filtragem do DataFrame utilizando o método isin() :
1
df_data[df_data['UF'].isin(lista_uf)]['UF'].unique()
 Retorno da filtragem direta do DataFrame
Retorno da filtragem direta do DataFrame df_data utilizando a lista lista_uf criada
Também podemos utilizar lista via método query(), da seguinte forma:
1
df_data.query('UF in @lista_uf')['UF'].unique()
Retorno da filtragem utilizando o método query() do DataFrame df_data utilizando a lista lista_uf criada
Para utilizarmos uma variável dentro do método
Query()precisamos utilizar o caractere@nome_variavel
Resumo
- Filtragem direta:
| Exemplo | Descrição |
|---|---|
df_data[df_data['UF'] == 'SP'] | Filtra onde UF é ‘SP’ |
df_data[df_data['Nota do Consumidor'] >= 3.0] | Filtra onde Nota do Consumidor é maior que 3.0 |
df_data[(df_data['UF'] == 'SP') & (df_data['Nota do Consumidor'] > 3.0)] | Filtra onde UF é ‘SP’ e a Nota do Consumidor é maior que 3.0 |
df_data[(df_data['UF'] == 'SP') \| (df_data['UF'] == 'RJ')] | Filtra onde UF é ‘SP’ ou ‘RJ’ |
- Vantagem: É mais fácil de entender e de usar.
- Desvantagem: Pode ser trabalhoso quando se tem muitas condições.
- Filtragem com
query()
| Exemplo | Descrição |
|---|---|
df_data.query("UF == 'SP'") | Filtra onde UF é ‘SP’ |
df_data.query("Idade > 30 and UF == 'SP'") | Filtra onde UF é ‘SP’ e a Idade é > 30 |
df_data.query("UF in ['SP', 'RJ']") | Filtra onde UF é ‘SP’ ou ‘RJ’ |
- Vantagem: Mais fácil de ler.
- Desvantagem: Pode ser menos flexível em expressões complexas e não pode se utilizar caracteres especiais.
- Filtragem com lista
isin()
| Exemplo | Descrição |
|---|---|
df[df['UF'].isin(['SP', 'RJ', 'MG'])] | Filtra onde UF é SP, RJ ou MG |
df[~df['UF'].isin(['SP', 'RJ'])] | Filtra onde UF NÃO é SP ou RJ |
- Vantagem: Útil para verificar múltiplos valores rapidamente.
- Desvantagem: Não permite operadores lógicos diretos (exemplo:
>ou<).
Para download do notebook utilizado, acesse o 🔗Link