Desbravando o Pandas - Parte 2 - Atribuindo valores e criando atributos
A continuação da explorção da biblioteca Pandas, desta vez mostrando como atribuir valores e como criar atributos.

Neste documento continuaremos explorarando os conceitos iniciais da biblioteca Pandas. Para acompanhamento utilizaremos a mesma base do 🔗Desbravando o Pandas - Parte 1 - Estrutura de dados e seguirei com as mesmas estruturas criadas previamente.
Atribuindo Dados
Atribuir dados significa modificar ou adicionar valores em um DataFrame ou Series. A forma como a atribuição é feita pode ter impactos significativos no comportamento, como criar cópias ou referências, alterar os dados originais ou gerar erros. Abaixo estão os principais conceitos e práticas.
Atribuindo Constantes
Ao fazermos uma atribuição de uma coluna de um DataFrame, como por exemplo a coluna Cidade no DataFrame df_data
1
df_data['Cidade']
 Valores da coluna Cidade do DataFrame
Valores da coluna Cidade do DataFrame df_data
Podemos fazer a atribuição de valores de duas formas, CÓPIA e REFERÊNCIA/VIEW. Para isso:
1
2
cidade_copy = df_data['Cidade'].copy() #Cópia da coluna Cidade
cidade_copy
 Valores da coluna Cidade copiados para a variável
Valores da coluna Cidade copiados para a variável cidade_copy
1
2
cidade_view = df_data['Cidade'] #Referência/View da coluna Cidade
cidade_view
 Valores da coluna Cidade referenciados para a variável
Valores da coluna Cidade referenciados para a variável cidade_view
E qual a diferença entre REFERÊNCIA/VIEW e CÓPIA? Caso alguma alteração no DataFrame original df_data seja feita, temos que:
Para exemplificar utilizando a função iloc, esta nos permite selecionar linhas e colunas no DataFrame com base em uma posição númerica, vamos alterar então a LINHA 0 e COLUNA 4, para isso podemos fazer da seguinte forma:
1
2
df_data.iloc[0,4] = 'Alterado' #Alterando o DataFrame original no índice 0 e coluna 4 para 'Alterado'
df_data.head(1) #Retornando apenas o primeiro índice
 Valores do Índice 0 e coluna 4 alterado
Valores do Índice 0 e coluna 4 alterado
Após a alteração, se buscarmos a CÓPIA teremos o seguinte:
1
cidade_copy
 Valores da variável
Valores da variável cidade_copy após alteração
Após a alteração, se buscarmos a REFERÊNCIA/VIEW teremos o seguinte:
1
cidade_view
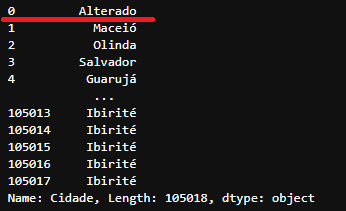 Valores da variável
Valores da variável cidade_view após alteração
Nota-se então, que os valores da CÓPIA se mantém mesmo após a alteração do DataFrame original df_data, enquanto a REFERÊNCIA por ser um ponteiro ao DataFrame original também tem seu valor alterado.
A escolha entre view (referência direta) e cópia (duplicação dos dados) no pandas depende do contexto em que você está trabalhando e dos objetivos da operação. Cada abordagem tem vantagens e desvantagens e deve ser usada com cuidado para evitar comportamentos inesperados ou problemas de desempenho.
Quando utilizar Referência/View?
Uma view é útil quando você quer manipular ou visualizar dados diretamente no DataFrame original sem duplicá-los na memória.
Casos comuns:
- Quando você deseja modificar valores existentes no DataFrame original.
- Quando você busca eficiência de memória, já que não existe a necessidade de duplicar estruturas.
- Usar views é eficiente para acessar partes de um DataFrame que você deseja processar ou analisar diretamente.
- Evitar duplicação acidental.
Quando utilizar Cópia?
Uma cópia cria um novo objeto com dados independentes, útil quando você precisa trabalhar com dados isolados do DataFrame original.
Casos comuns:
- Se você deseja processar ou transformar os dados sem impactar o DataFrame original.
- Evitar efeitos colaterais inesperados.
- Comparar antes e depois de alguma alteração.
- Isolamento de processamento paralelo (Em pipelines de dados ou processos paralelos, criar cópias ajuda a evitar conflitos entre threads ou funções).
- Usar uma cópia garante que mudanças feitas por terceiros não afetem sua análise.
Boas práticas
- Garanta a Intenção: Use
copy()explicitamente se não quiser modificar o DataFrame original. - Evite Substituições Desnecessárias: Modifique valores in-place usando .
locouilocquando possível. - Leia Warnings: O
SettingWithCopyWarningavisa quando o pandas detecta operações ambíguas entre views e cópias.
| Situação | Use View | Use Cópia |
|---|---|---|
| Modificar dados direto no DataFrame | ✔️ Sim | ❌ Não |
| Manter dados originais intactos | ❌ Não | ✔️ Sim |
| Evitar uso excessivo de memória | ✔️ Sim | ❌ Não |
| Comparar dados antes e depois de alguma alteração | ❌ Não | ✔️ Sim |
| Trabalhar em subconjunto temporário | ✔️ Sim | ❌ Não |
| Isolamento entre processos e threads | ❌ Não | ✔️ Sim |
Atribuindo Listas ou Series
O nosso DataFram df_data contém 105018 linhas e 30 colunas, para fazer a alteração de uma coluna inteira precisamos de uma Series contendo o mesmo número de linhas existente na coluna objetivo ou seja, uma lista contendo 105018
1
2
n_linhas, n_colum = df_data.shape
n_linhas, n_colum
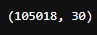 Resultado da execução
Resultado da execução df_data.shape, com a dimensão do DataFrame criado df_data, contendo 105018 linhas e 30 colunas
Para criação destes 105018 valores de uma coluna utilizaremos LIST COMPREHENSION, que é uma forma de criar listas a partir de outras listas, usando uma notação matemática.
1
2
novas_cidades = [f'Cidade {i}'for i in range(n_linhas)]
len(novas_cidades) #Retorna o número de itens de um objeto, como uma lista, string, tupla, dicionário ou qualquer sequência
 Quantidade de valores após criação da lista
Quantidade de valores após criação da lista novas_cidades
A lista
novas_cidadesrecebe um looping de 0 até o número de linhas do DataFramedf_data, onde cada passagem a string ‘Cidade ‘ é concatenado com o valor do índice da passagem i
A quantidade de elementos na lista novas_cidades é igual ao número de linhas do DataFrame df_data, podemos então fazer a substituição dos valores da coluna Cidade para o novo valor.
1
2
df_data['Cidade'] = novas_cidades #Substituindo os valores da coluna Cidade pelos valores da lista novas_cidades
df_data.head()
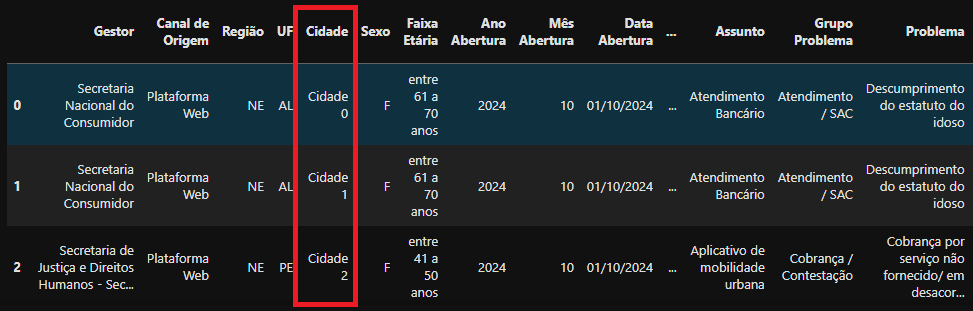 Valores trocados após alteração para
Valores trocados após alteração para novas_cidades
Para retornarmos os dados de Cidade originais, podemos utilizar a cópia feita na Series cidade_copy, esta Series foi criada e copiada antes da alteração da coluna, portanto tem os valores originais da mesma.
1
2
df_data['Cidade'] = cidade_copy #Retornando os valores originais da coluna Cidade utilizando a cópia feita antes da alteração
df_data.head()
 Valores retornados para o origal utilizando a cópia feita em
Valores retornados para o origal utilizando a cópia feita em cidade_copy
Criando novas colunas
No pandas, criar novas colunas em um DataFrame é uma tarefa comum, essencial para enriquecer os dados com informações derivadas, categorizações ou transformações. Essa operação é direta, mas oferece muitas possibilidades.
Para se criar uma nova coluna em um DataFrame é necessário atribuirmos uma lista/Series de valores ou uma constante a uma nova chave do DataFrame. Da mesmo forma da atribuição, a quantidade de valores da lista precisa ser igual ao número de linhas totais do DataFrame.
Criando colunas a partir de valores constantes
Para criar colunas a partir de um valor constante, ou seja, todas as linhas terão o mesmo valor para esta nova coluna podemos:
1
2
df_data['Coluna Constante'] = 'Valor Constante'
df_data.head(3)
 Retorno do
Retorno do df_data após a criação da nova coluna Coluna Constante
Agora, a nova coluna Coluna Constante foi criada e ela contém em todas as 105018 linhas o mesmo valor, neste caso a string ‘Constante’.
Criando colunas a partir de uma lista
Para criar colunas a partir de uma lista pré definida, basta atribuir ao DataFrame o novo campo com a lista.
1
2
df_data['Coluna Lista'] = range(df_data.shape[0])
df_data.head(3)
 Retorno do
Retorno do df_data após a criação da nova coluna Coluna Lista
Agora, a nova coluna Coluna Lista foi criada e ela contém em todas as 105018, neste caso o intervalo entre número 0 até 105017.
Criando colunas a partir de uma lista menor
Se tentarmos atribuir uma lista menor do que a quantidade de linhas totais do DataFrame teremos um problema de Match. Exemplo, se tentarmos atribuir uma lista de 3 itens no DataFrame df_data:
1
df_data['Lista Menor'] = [1,2,3]
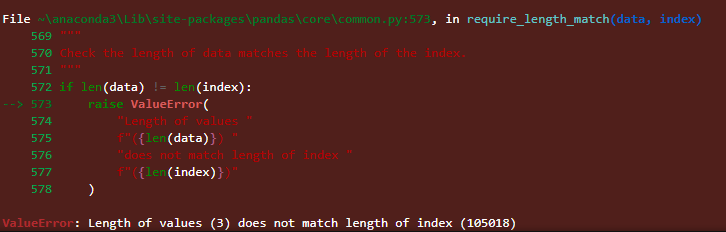 Erro retornado após a tentativa de criação da nova coluna
Erro retornado após a tentativa de criação da nova coluna Lista Menor
Criando colunas a partir de outras colunas
Uma coluna pode ser criado com base em calculos matemátios e/ou condicionais dependentes de outros campos. Por exemplo, se tentarmos criar uma nova coluna chamada Nova Nota Consumidor onde o valor dela é a multiplicação do campo Nota Consumidor * 2, fariamos o seguintes:
1
2
df_data['Nova Nota do Consumidor'] = df_data['Nota do Consumidor'] * 2
df_data.head(3)
 Retorno do
Retorno do df_data após a criação da nova coluna Nova Nota do Consumidor
Criando colunas condicionais
Uma coluna pode ser criado com base em condicionais dependentes de outros campos. Por exemplo, se tentarmos criar uma nova coluna chamada Coluna Condicional onde o valor dela é dependente do valor do campo Nova Nota do Consumidor sendo que, caso este seja maior ou igual a 5 retorna ‘Boa’ caso contrário Ruim:
1
2
df_data['Coluna Condicional'] = np.where(df_data['Nova Nota do Consumidor'] >= 5, 'Boa','Ruim')
df_data.head(3)
Neste caso precisamos utilizar a biblioteca
numpyna qual será tratada posteriormente
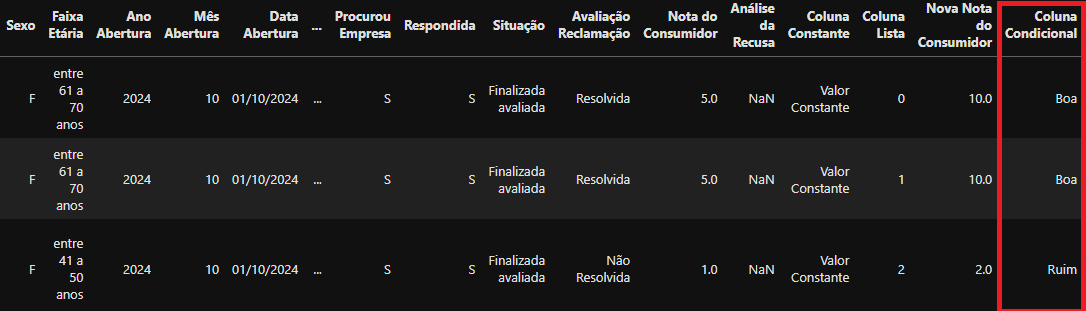 Retorno do
Retorno do df_data após a criação da nova coluna Coluna Condicional
Dropando campos
Para fazer o drop de campos que não serão utilizados no DataFrame, basta utilizar o método drop(), da seguinte forma:
1
2
3
4
df_data.drop(['Coluna Constante','Coluna Lista','Nova Nota do Consumidor'], axis=1, inplace=True)
df_data.head(3)
## O atributo axis(0|1) serve para indicarmos se a exclusão sera coluna ou linha
## O Atributo inplace(True|False) serve para descartar a necessidade de criação de um novo DataFrame
 Retorno do
Retorno do df_data após a remoção das novas colunas Coluna Constante, Coluna Lista e Nova Nota do Consumidor
Quais as vantagens de se dropar campos de um DataFrame?
- Flexibilidade : Funciona tanto para remover linhas quanto colunas, com uma sintaxe consistente.
- Controle sobre modificações : Com
inplace=False(padrão), mantém o DataFrame original intacto, retornando uma nova cópia com as alterações. - Limpeza de dados : Facilita a remoção de dados indesejados ou irrelevantes, ideal para remoção de colunas redundantes ou outliers.
- Evita problemas de inconsistência : Ajuda a evitar falhas em pipelines de dados.
Para download do notebook utilizado, acesse o 🔗Link