Desbravando o Pandas - Parte 1 - Estrutura de dados
Ao longo deste post, exploraremos os conceitos básicos para manipulação de dados começando com a importação de base de dados e a criação do primeiro Data Frame.

Neste post (E em outros) exploraremos os conceitos iniciais para se começar a entender sobre manipulação de dados/engenharia de dados e sobre principalmente sobre o funcionamento da biblioteca Pandas.
A manipulação de dados é uma habilidade essencial para quem trabalha com ciência de dados, análise de dados ou qualquer área que envolva a extração e tratamento de dados a partir de informações brutas. Entender como importar bases de dados e estruturar essas informações em um Data Frame é o primeiro passo de um longo caminho até até a plena manipulação dos dados. Neste post, abordaremos esses conceitos básicos, fornecendo uma base sólida para iniciantes darem os primeiros passos na manipulação de dados de forma prática e eficiente.
O que é o Pandas?
O Pandas é uma biblioteca de código aberto para a linguagem Python amplamente utilizada para manipulação, análise e exploração de dados. Ela oferece estruturas de dados práticas para este fim, como DataFrame e Series, que facilitam o trabalho com dados tabulares e séries temporais, entre outros tipos.
 Python - Pandas
Python - Pandas
Principais caracteristicas da biblioteca Pandas:
- Estrutura de Dados
- DataFrame: Uma tabela bidimensional (linhas e colunas), semelhante a uma planilha do Excel ou uma tabela SQL.
- Series: Uma estrutura unidimensional, como uma coluna de um DataFrame ou um vetor.
- Funcionalidades
- Leitura e escrita de dados: Suporte a diversos formatos como CSV, Excel JSON, SQL, e até arquivos de texto.
- Manipulação de dados: Permite filtrar, agrupar, unir, pivotar e transformar dados.
- Tratamento de dados ausentes: Oferece métodos para identificar, substituir ou remover valores nulos.
- Estatísticas descritivas: Ferramentas para calcular métricas básicas como média, soma, contagem e desvio padrão.
- Integração com outras bibliotecas: Funciona bem com NumPy, Matplotlib e outras ferramentas do ecossistema Python.
Se você trabalha com análise de dados ou ciência de dados, aprender a usar o Pandas é um passo essencial para lidar com dados de forma estruturada e eficiente.
Dataset utilizado
Para este post utilizaremos a base fornecida pelo site Consumidor.gov. O dataset em questão contém as reclamações do mês de dezembro de 2024 dos consumidores a alguma empresa que atua no Brasil.
| Info | Descrição |
|---|---|
| Criado | 07/01/2025 |
| Formato | .csv |
| Tipo | .zip |
| Download | 🔗Link Download |
| Conteúdo | A base contém informações como [‘Gestor’, ‘UF’, ‘Cidade’, ‘Faixa Etária’, ‘Data Abertura’, ‘Nome Fantasia’, ‘Assunto’, ‘Nota do Consumir’] |
Importando a base de dados
Para carregar um arquivo no formato csv, basta utilizar a função read_csv()
1
df_data = pd.read_csv('./Base de dados/ConsumidorGov.csv',sep = ';')
Para mostrar o dado carregado, basta executar a variavel criada contendo o Data Frame df_data. No meu caso buscarei apenas as 5 primeiras linhas do df da seguinte forma:
1
df_data.head(5)
Após execução dos blocos de código acima, o seguinte resultado da função deve ser retornado:
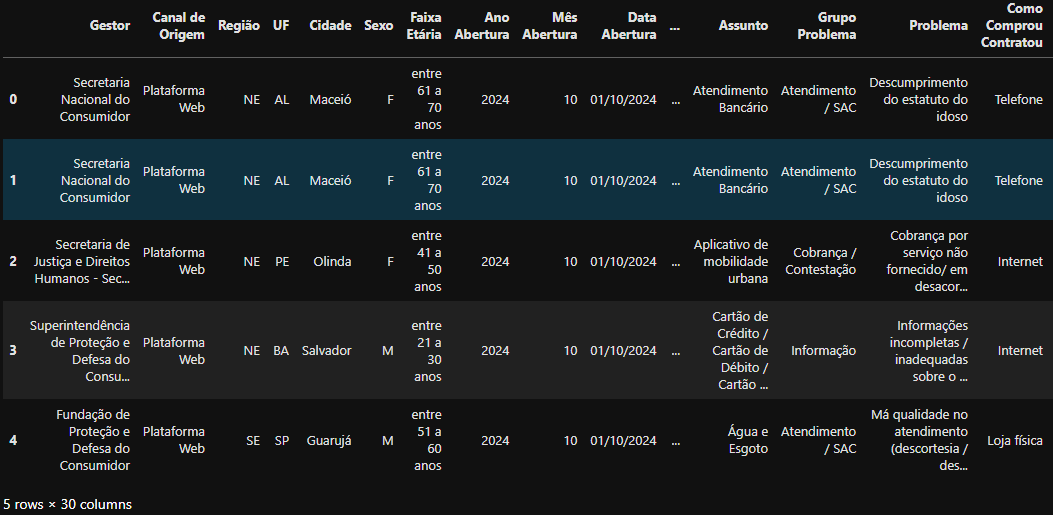 Resultado da execução
Resultado da execução df_data.head(5), na qual, as 5 primeiras linhas do DataFrame df_data foram retornadas
Da mesma forma que a função
head(n)retorna a cabeça(Primeiras n linhas) do DataFrame, a funçãotail(n)retorna a calda(Últimas n linhas) do DataFrame
Exibindo informações sobre o DataFrame
Para verificar algumas informações úteis do DataFrame basta utilizar a função info(), da seguinte forma:
1
df_data.info()
O seguinte resultado deve ser retornado:
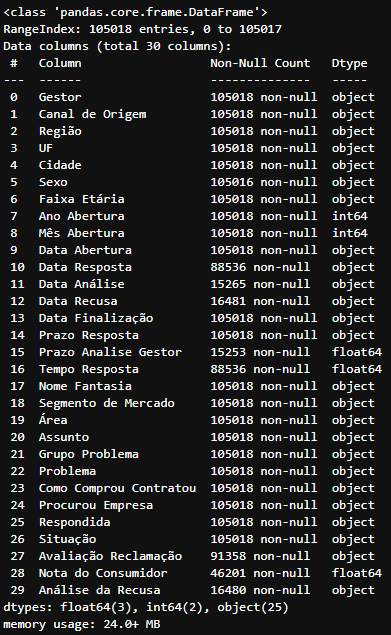 Resultado da execução
Resultado da execução df_data.info()
A função info() do Pandas exibe informações detalhadas sobre um DataFrame. Ela é útil para:
- Verificar se existem dados nulos.
- Identificar problemas como dados inconsistentes.
- Entender quais tipos de dados estão presentes.
- Obter uma rápida descrição dos dados.
Ela exibe informações como o número de linhas, número de colunas, tipo de dados de cada coluna, quantidade de dados não nulos em cada coluna e uso de memória.
Neste exemplo, o DataFrame
df_datacontém 105018 linhas com seu index variando de 0 até 105017, um total de 30 colunas sendo 3 do tipo float64, 2 do tipo int64 e 25 do tipo object. O DataFrame tem em torno de 24.0mb de uso de memória.
Outra função interessante para exibição de informações do DataFrame é a columns(), esta retorna os nomes das colunas de um DataFrame.
1
df_data.columns
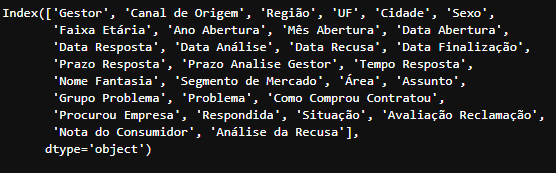 Resultado da execução
Resultado da execução df_data.columns, com o nome de todas as colunas pertencente ao DataFrame criado df_data
Para saber as dimensões do Data Frame (Número de linhas x Número de colunas) utilizamos a funçao shape do Data Frame.
1
df_data.shape
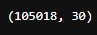 Resultado da execução
Resultado da execução df_data.shape, com a dimensão do DataFrame criado df_data, contendo 105018 linhas e 30 colunas
Criando um DataFrame
O que é um Data Frame? Um data frame é uma estrutura de dados utilizada em linguagens de programação como R e Python para armazenar e manipular dados tabulares, bidimensionais, ou seja, organizados em linhas e colunas.
Os DataFrames são úteis para:
- Analisar dados.
- Preparar dados para modelos de machine learning.
- Manipular dados não relacionados ao machine learning.
- Realizar operações matemáticas, como adição, subtração, multiplicação e divisão.
Os DataFrames podem ser criados do zero, a partir de outras estruturas de dados ou importados de várias fontes de dados.
O dataset carregado na variável df_data é do tipo Data Frame e isso pode ser confirmado pela função type():
1
type(df_data)
 Resultado da execução
Resultado da execução type(df_data) contendo o tipo da estrutura de dados da variável df_data
Criando um DataFrame a partir de um dicionário
Podemos criar um Data Frame utilizando um dicionário, dessa forma, cada chave possuirá uma lista de elementos de igual tamanho.
1
2
3
4
5
alunos_df = pd.DataFrame({
'nome' : ['Lucas', 'Andressa', 'Bruno'],
'idade' : [30,28,35],
'peso' : [72,58,120]
})
que conterá a seguinte estrutura:
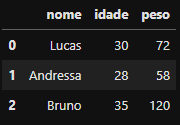 Resultado da execução
Resultado da execução alunos_df contendo o DataFrame criado a partir de um diconário pela função pd.DataFrame()
Criando uma Series
Uma Series no Pandas é uma estrutura de dados unidimensional que armazena dados de qualquer tipo. É semelhante a uma coluna de uma tabela, e é uma das estruturas de dados principais da biblioteca Pandas.
As Series são muito úteis para:
- Manipular dados.
- Filtrar dados.
- Calcular dados.
- Guardar dados sobre um atributo em particular no dataset.
Para Recuperar/Selecionar uma COLUNA inteira do DataFrame basta:
1
alunos_df['idade']
A coluna inteira, com todas as linhas de idade serão retornados:
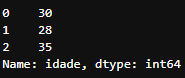 Resultado da recuperação da coluna idade do DataFrame
Resultado da recuperação da coluna idade do DataFrame alunos_df
Este retorno é do tipo Series, podendo ser observado pela função type():
 Tipo da coluna recuperada
Tipo da coluna recuperada
Para Recuperar/Selecionar uma LINHA inteira do DataFrame basta utilizar o atributo iloc[n], da seguinte forma:
1
alunos_df.iloc[1]
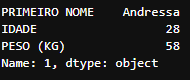 Resultado da recuperação da linha com index 1 do DataFrame
Resultado da recuperação da linha com index 1 do DataFrame alunos_df
Para criar uma nova Series a partir de uma lista de elementos (Sem a utilização de um DataFrame), basta utilizar a função Series.
1
pd.Series([1,10,100,1000])
Desta forma a seguinte Series foi criada:
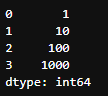 Series criada com os valores 1,10,100,1000
Series criada com os valores 1,10,100,1000
Podemos também alterar o nome dos índices da Series utilizando o atributo index no momento da criação da Series:
1
pd.Series([1,10,100,1000], index=['um','dez','cem','mil'])
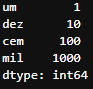 Series criada com os valores 1,10,100,1000 e com os index um, dez, cem, mil
Series criada com os valores 1,10,100,1000 e com os index um, dez, cem, mil
Também podemos alterar o nome da Series utilizando o atributo name no momento da criação da Series:
1
pd.Series([1,10,100,1000], index=['um','dez','cem','mil'], name='Números')
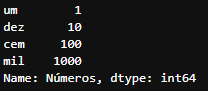 Series criada com os valores 1,10,100,1000 e com os index um, dez, cem, mil e com o nome *Números*
Series criada com os valores 1,10,100,1000 e com os index um, dez, cem, mil e com o nome *Números*
Para download do notebook utilizado, acesse o 🔗Link