Desbravando o Airflow - Parte 1 - Configurando ambiente e instalação
Aprenda a configuração de um ambiente mínimo necessário para instalação do Apache Airflow.

Introdução
Com o crescimento exponencial dos dados, a necessidade de processá-los de forma eficiente nunca foi tão importante. Empresas e profissionais de dados enfrentam desafios constantes para extrair informações a partir de grandes volumes de dados armazenados em bancos relacionais, planilhas e outros formatos.
Neste (E nos próximos) artigo, vamos explorar a construção de um pipeline de dados, começando pela configuração de uma instância ec2 e instalação do Apache Airflow.
Vamos entender como essa ferramenta se complementa com outras para criação um fluxo de dados robusto e para garantir que tudo funcione de forma automática e escalável, utilizaremos o Apache Airflow para orquestrar o pipeline, agendar execuções e monitorar possíveis falhas.
Ao final destes posts, você terá um pipeline funcional que pode ser adaptado para diversos cenários, seja para processar dados de vendas, logs de sistemas ou qualquer outro conjunto de informações estruturadas.
O que é o Apache Airflow?
O Apache Airflow é uma ferramenta de código aberto para orquestração de fluxos de trabalho. Ele permite criar, agendar e monitorar pipelines de dados de maneira programável e escalável. O Airflow é amplamente utilizado para automação de processos ETL, movimentação de dados entre sistemas e integração de ferramentas em um fluxo unificado.

Apache Airflow Logo
Principais características
- Baseado em DAGs (Directed Acyclic Graphs) – Fluxos de trabalho são representados como grafos direcionais acíclicos, onde cada nó representa uma tarefa/atividade a ser executada.
- Possui interface amigável e permite agendar tarefas e visualizar execuções via interface web.
- Suporte a operadores personalizados e integração com diversos serviços como AWS, Google Cloud, Databricks e outros.
- Pode ser escalado horizontalmente, distribuindo tarefas entre múltiplos workers.
- Tarefas e pipelines são definidos em código Python, garantindo flexibilidade e controle.

Apache Airflow Model
Casos de uso
- ETL/ELT – Extração, transformação e carga de dados.
- Orquestração de Machine Learning – Automação de pipelines de treinamento e inferência.
- Integração de Dados – Movimentação de dados entre bancos SQL, NoSQL, APIs e sistemas de armazenamento.
- Automação de Processos – Gatilhos e dependências entre sistemas empresariais.
O que é o AWS EC2?
O AWS EC2 (Elastic Compute Cloud) é um serviço da Amazon Web Services (AWS) que fornece máquinas virtuais na nuvem. Ele permite que você crie e gerencie servidores virtuais (chamados de instâncias) sob demanda, pagando apenas pelo tempo de uso.

Amazon EC2 Logo
Principais características
- Escalabilidade – Você pode aumentar ou diminuir a capacidade conforme necessário.
- Modelos de Instância – Oferece instâncias otimizadas para diferentes cargas de trabalho (CPU, memória, armazenamento, GPU, etc.).
- Opções de Preço – Inclui On-Demand (pagamento por hora/segundo), Reserved Instances (contratos de longo prazo mais baratos), Spot Instances (descontos em servidores ociosos) e Savings Plans.
- Segurança – Integração com VPC (Virtual Private Cloud), IAM (Identity and Access Management) e outras ferramentas de segurança.
- Flexibilidade de SO – Suporte a Linux, Windows e outros sistemas operacionais.
 Sistemas operacionais suportados
Sistemas operacionais suportados
Casos de uso
- Hospedagem de aplicações e sites.
- Execução de bancos de dados e sistemas distribuídos.
- Treinamento de modelos de Machine Learning.
- Simulações e processamento de dados intensivos.
- Desenvolvimento e testes de software.
Apache Airflow + AWS EC2
Usar AWS EC2 para hospedar o Apache Airflow é uma abordagem comum para quem deseja ter controle total sobre a configuração do Airflow, sem depender de soluções gerenciadas mais robustas.
Essa abordagem funciona bem para projetos pequenos e médios. Para workloads mais complexos, você pode considerar o MWAA (Managed Workflows for Apache Airflow) para evitar gerenciar a infraestrutura manualmente.
Arquitetura Básica
 Apache Airflow + AWS EC2
Apache Airflow + AWS EC2
Para esta etapa utilizaremos a seguinte arquitetura e seguiremos os seguintes passos:
- Instância EC2 – Criação e configuração de uma instância EC2 (Ubunto Pro 22.04).
- Instalação Apache Airflow – Instalação e configuração do Apache Airflow na instância criada na etapa anterior.
- Metadados – O Airflow precisa de um banco relacional para armazenar metadados (Usaremos PostgreSQL).
- Executores – Configuração do executor local.
- Scheduler e Webserver – O Airflow precisa de um agendador para gerenciar tarefas e de um webserver para a interface gráfica.
Criando a instância EC2
Vamos passar pelo passo a passo para criar uma instância EC2, configurar suas principais definições e acessá-la remotamente.
1. Acessando o serviço EC2
Após acessar o console da AWS, caso seja a sua primeira vez fazendo a visita busque por EC2 na caixa de pesquisa do console.
 Caixa de pesquisa do console AWS
Caixa de pesquisa do console AWS
Caso não seja a sua primeira vez visitando as instâncias da AWS, você pode encontrar o serviço em Visitado Recentemente
 Visitado Recentemente do console AWS
Visitado Recentemente do console AWS
No painel da Amazon EC2, o primeiro passo é executar uma instância, selecionando o seguinte botão na home page do painel
 Painel Amazon EC2
Painel Amazon EC2
2. Configurando a instância
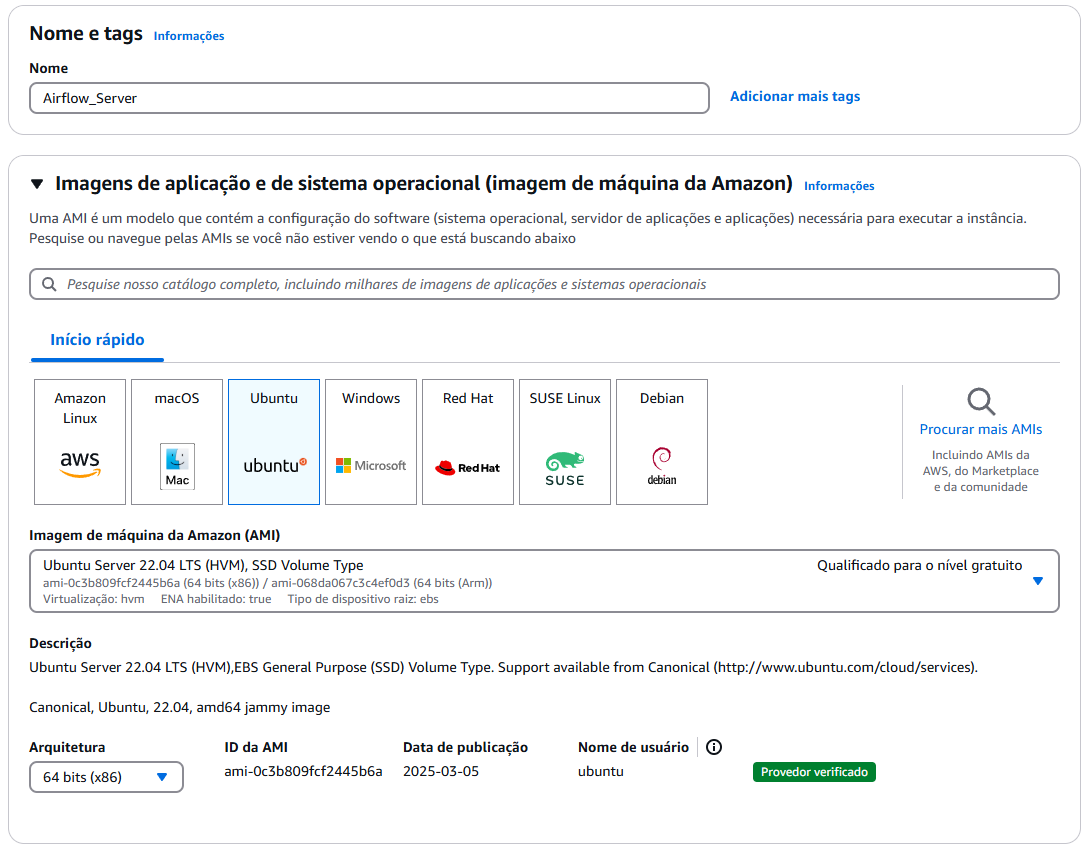 Configurações iniciais
Configurações iniciais
1. Defina um nome para sua instância. No meu caso a instância será “Airflow_Server”.
2. Defina o Sistema Operacional a ser utilizado na sua instância. No nosso caso selecione o Ubunto Pro.
A melhor opção atualmente é o Ubuntu Pro, por conter compatibilidade total com o Apache Airflow, Python, Docker e PostgreSQL. Para mais informações acesse a documentação do Apache Airflow pelo seguinte 🔗Link.
3. Definina a imagem do Sistema Operacional para 22.04 LTS.
A melhor opção de imagem atualmete é a 22.04 LTS, por conter maior suporte e estabilidade. A imagem 24.04 por ser um lançamento mais recente pode conter instabilidades.
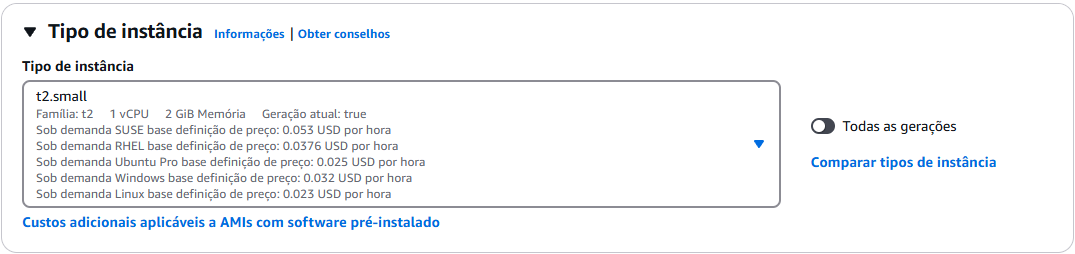 Tipo da instância
Tipo da instância
4. Selecione o tipo da instância para T2.Small ou maior.
Para uma boa utilização do Apache Airflow na sua instância o aconselhado é no mínimo 2GiB de memória. Fique atento, qualquer tipo maior ou igual ao T2.Small pode ser COBRADO, para mais inforamção acesse a calculadora de preços da AWS no seguinte 🔗Link.
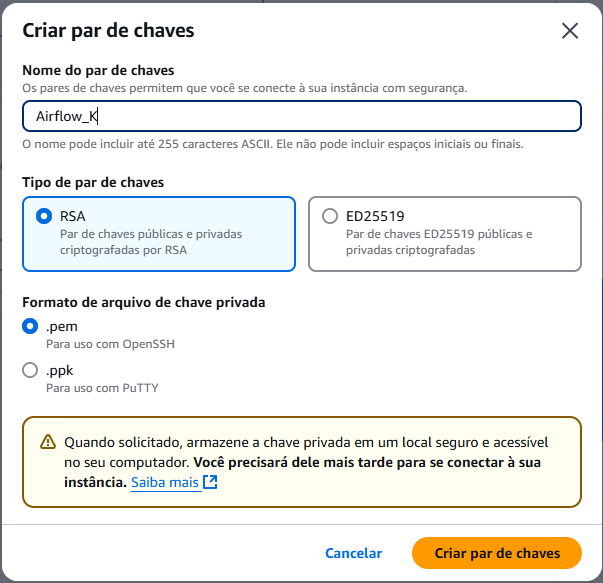 Par de chaves
Par de chaves
5. Crie um novo par de chaves para acesso a sua instância.
- Selecione o tipo de par de chave como
RSA; - Selecione o formato da chave como
.pem; - Clique em
Criar par de chaves;
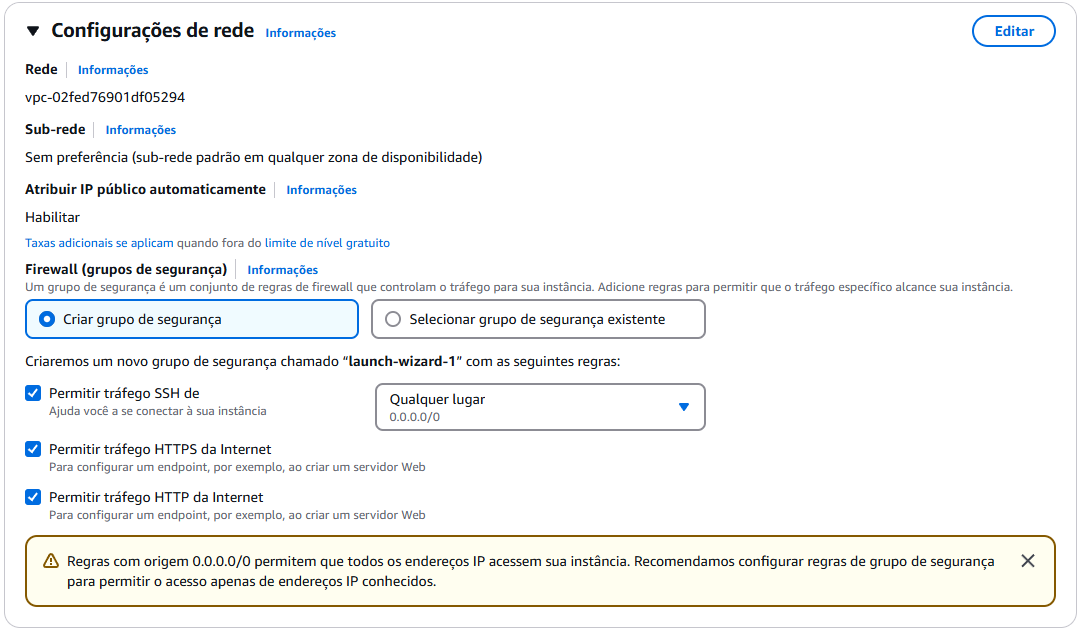 Configuração da rede
Configuração da rede
6. Para o nosso uso, ative:
- Permissão para
SSH; - Permissão para
HTTPs; - Permissão para
HTTP;
Para o nosso objetivo/case de uso essa configuração já é o suficiente. Mas saiba que existe outros meios de acesso mais seguros para produção, para mais informações acesse a documentação do Apache Airflow pelo seguinte 🔗Link.
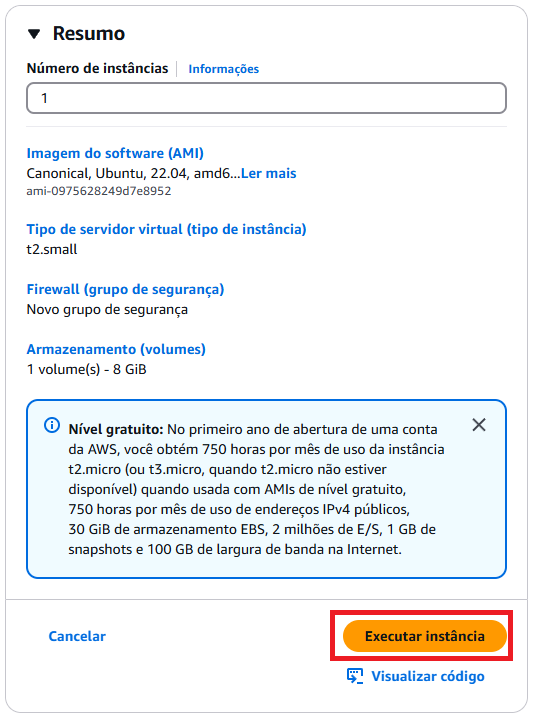 Resumo Instância
Resumo Instância
7. Confira o resumo da instância a ser criada e caso tudo esteja conforme seu desejo selecione Executar instância.
 Instância criada
Instância criada
8. Aguarde a criação da instância.
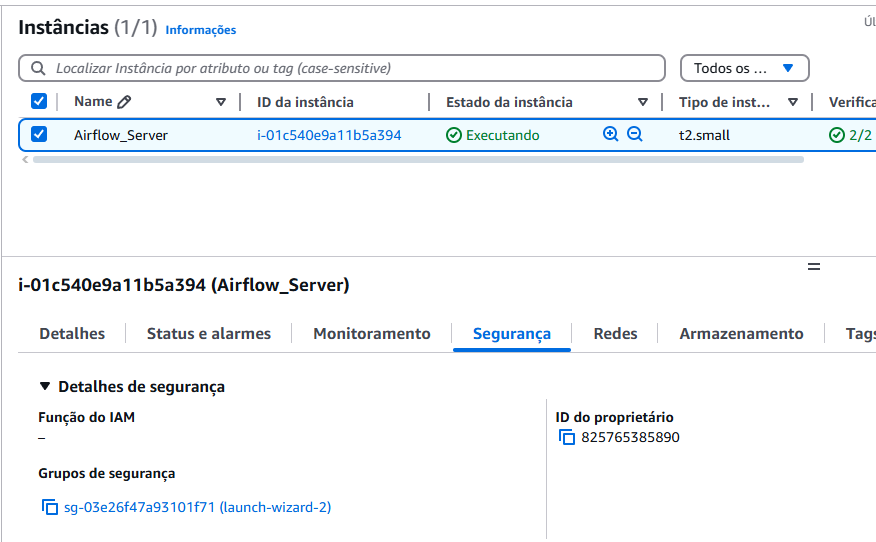 Aba Segurança
Aba Segurança
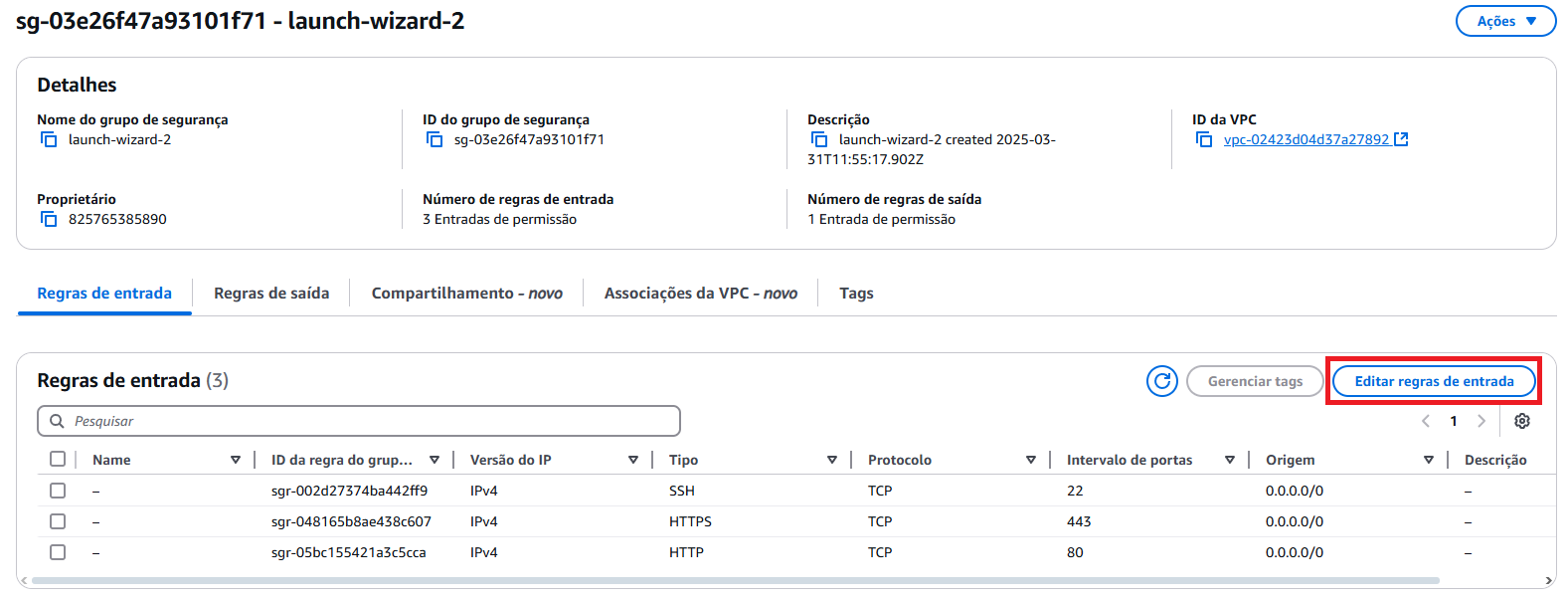 Editar regras
Editar regras
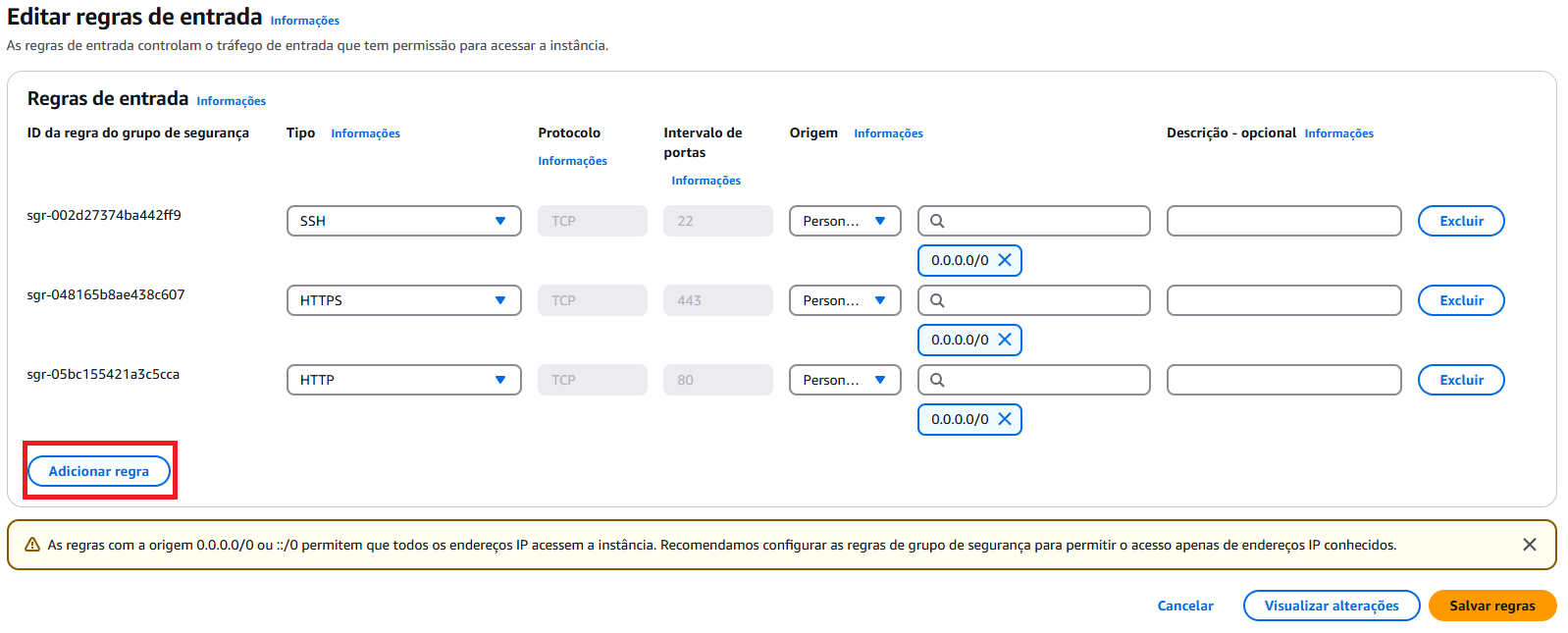 Criar nova regra
Criar nova regra
9. Selecione a aba Segurança da instância criada.
- Vá em
Editar regras de entrada; - Vá em
Adicionar regra; - Crie uma regra com as seguintes especificações (TCP Personalizado e porta 8080);
 Regra criada
Regra criada
10. Pronto, a instância foi configugurada e criada. Para acessar, basta selecionar a instância e ir em Conectar.
Instalando o Apache Airflow
 Acesso
Acesso
Após acessar a instância criada nos passos anteriores, rode os seguintes comandos na ordem.
1. Atualize a lista de pacotes disponíveis.
1
sudo apt update
2. Instale o gerenciador de pacotes pip para python 3.
1
sudo apt install python3-pip
3. Instale o SQLite3.
1
sudo apt install sqlite3
4. Instale o módulo venv para criar ambientes virtuais no Python 3.10.
1
sudo apt install python3.10-venv
5. Crie um ambiente virtual chamao venv (Ou qualquer outro nome que desejar) para isolar as dependências no Python.
1
python3 -m venv venv
6. Ativa o ambiente virtual criado no passo anterior venv, permitindo o uso de pacotes intalados dentro dele.
1
source venv/bin/activate
7. Instale a biblioteca de desenvolvimento do PostgreSQL (Opcional se não for utilizar PostgreSQL como banco para os metadados, necessário para compilar extensões que interagem com o banco de dados PostgreSQL).
1
sudo apt-get install libpq-dev
8. Instala o Apache Airflow na versão 2.5.0 com suporte ao PostgreSQL, garantindo compatibilidade com as dependências especificadas no arquivo para Python 3.7.
1
pip install "apache-airflow[postgres]==2.5.0" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.5.0/constraints-3.7.txt"
Outras dependências podem ser utilizadas, verificar instalação pelo 🔗Link.
9. Inicialize o banco de daddos do Apache Airflow, criando as tabelas necessárias para o funcionamento do sistema.
1
airflow db init
10. Instale o PostgreSQL e pacotes adicionais com funcionalidades extras para o banco de dados.
1
sudo apt-get install postgresql postgresql-contrib
11. Mude para o usuário do sistema postgres, permitindo executar comandos administrativos no PostgreSQL.
1
sudo -i -u postgres
12. Abra o terminal interativo do PostgreSQL.
1
psql
13. Crie um banco de dados e um usuário para o Airflow no PostgreSQL e garanta todos os privilégios sobre o banco criado.
1
2
3
CREATE DATABASE airflow;
CREATE USER airflow WITH PASSWORD 'airflow';
GRANT ALL PRIVILEGES ON DATABASE airflow TO airflow;
14. Saia do terminal do PosgreSQL utilizando Ctrl + D e Ctrl + D (2x).
15. Entre no diretório criado airflow.
1
cd airflow
16. Substitua a string de conexão no arquivo airflow.cfg por PostgreSQL ao invés de SQLite.
1
sed -i 's#sqlite:////home/ubuntu/airflow/airflow.db#postgresql+psycopg2://airflow:airflow@localhost/airflow#g' airflow.cfg
17. Verifique se a string de conexão foi alterada.
1
grep sql_alchemy airflow.cfg
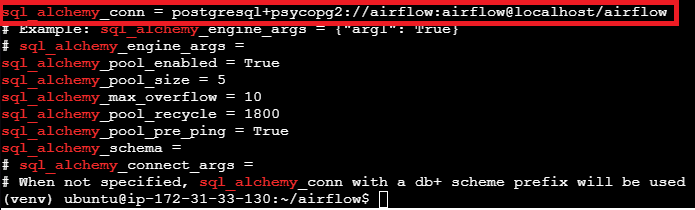 Verifique se a conexão foi alterada para PostgreSQL
Verifique se a conexão foi alterada para PostgreSQL
18. Verifique se o tipo de executor do Airflow é do tipo SequentialExecutor.
1
grep executor airflow.cfg
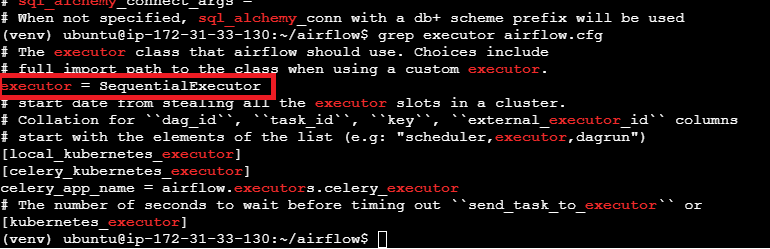 Verifique o tipo do executor
Verifique o tipo do executor
19. Substitua o método do executor para LocalExecutor.
1
sed -i 's#SequentialExecutor#LocalExecutor#g' airflow.cfg
20. Verifique se o tipo de executor foi alterado.
1
grep executor airflow.cfg
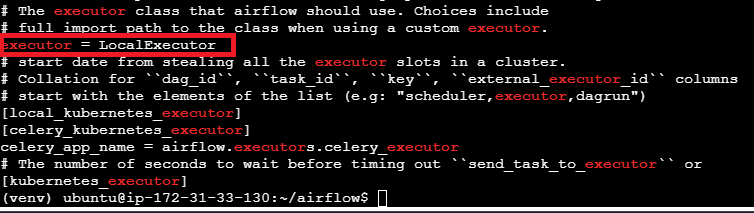 Verifique o tipo do executor foi alterado
Verifique o tipo do executor foi alterado
21. Crie o diretório para armazenamento dos DAGS.
1
mkdir dags
22. Inicie novamente o banco de dados do Airflow.
1
airflow db init
23. Crie um usuário do Airflow.
- Login:
airflow - Senha:
airflow
1
airflow users create -u airflow -f airflow -l airflow -r Admin -e airflow@gmail.com
24. Inicie o servidor web para interface gráfica.
1
airflow webserver &
25. Inicie o agendador do Airflow.
1
airflow scheduler
Se na execução de todos os comandos nenhum erro foi retornado, o apache foi instalado e configurado para acesso via navegador. Basta copiar o IPv4 DNS da sua instância EC2 e colar no navegador da seguinte forma http://seu-dns-ipv4:8080. Obtendo então a seguinte tela:
 Login Apache Airflow
Login Apache Airflow
Criando o primeiro DAG
Vamos criar o primeiro DAG para teste do airflow, para isso crie um arquivo dentro da pasta airflow/dags utilizando o seguinte comando
1
nano my_first_dag.py
Copie e cole o seguinte código
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from datetime import datetime
default_args = {
'owner': 'airflow',
'start_date': datetime(2025, 1, 1),
'retries': 1,
}
dag = DAG(
'my_first_dag',
default_args=default_args,
schedule_interval='@daily',
)
start = DummyOperator(task_id='start', dag=dag)
end = DummyOperator(task_id='end', dag=dag)
start >> end
No próximo post, trataremos melhor sobre o assunto de DAG (Directed Acyclic Graph). Portanto, não se apegue a este tópico por enquanto.
Abra a interface gráfica no navegador e faça o login utilizando as credênciais criadas a pouco (No meu caso Login: airflow e Senha: airflow)
Login Apache Airflow
Encontre a DAG criada my_first_dag e inicie a sua execução, se nenhum erro ocorrer você verá algo parecido com o retorno a seguir:
 DAG
DAG my_first_dag agendada sem nenhum erro
Parabéns! 🎉🎉🎉 Agora que seu primeiro DAG foi criado no Apache Airflow, você deu o primeiro passo para automatizar fluxos de dados e orquestrar tarefas de forma mais eficiente.
Com essa estrutura inicial, você pode:
- Executar e monitorar tarefas diretamente pela interface web do Airflow.
- Adicionar dependências e agendamentos, tornando seu fluxo mais dinâmico.
- Integrar com bancos de dados, APIs e outras ferramentas para processar dados de forma escalável.
Nosso próximo passo será entender mais sobre a estrutura do DAG, operadores e conexões para tornar seus pipelines mais robustos e automatizados.